Класс точности станка | MoscowShpindel
На каждом виде станков проводится испытание на соответствие норме точности. Результаты испытания записываются в акт, который вкладывается в паспорт станка. Каждый тип станков имеет ГОСТ, который регламентирует допустимые отклонения во всех проверках. Количество проверок для разных типов станков бывает различным. Некоторые модели настольных широкоуниверсальных фрезерных станков с ЧПУ имеют несколько десятков проверок. Все станки классифицируются по точности работы делением на классы:
- На станках нормальной точности обрабатываются заготовки из проката, литья и поковок. Обозначаются буквой Н.
- На станках повышенной точности (они выпускаются на базе станков с нормальной точностью, но их монтаж отличается особой тщательностью) можно обрабатывать заготовки такого же производства, но с более точным выполнением всех работ. Обозначаются буквой П.
- На станках высокой точности (обозначаются буквой В) и особо высокой точности (буквой

- На особо точных станках можно достичь наивысшей точности обработки очень ответственных деталей: делительных дисков, зубчатых колес, измерительного инструмента и других видов. Обозначаются буквой С.

Допустимые отклонения по проверкам соседних классов точности станков отличаются друг от друга в 1,6 раза. Вот таблица величин допускаемых отклонений при прямолинейном движении для станков, имеющих различный класс точности.
Класс точности станка | ||||||||
| Н | П | В | А | С | ||||
Допустимые отклонения, микроны | ||||||||
| 10 | 6 | 4 | 2,5 | 1,6 | ||||
ГОСТ 8-82 для всех видов металлорежущих станков, в том числе и настольных с ЧПУ, устанавливает стандарт общих требований к испытаниям на точность. По нему точность всех станков этого типа определяется по трем группам показателей:
По нему точность всех станков этого типа определяется по трем группам показателей:
- точность обработки испытываемых образцов;
- геометрическая точность самих станков;
- дополнительные показатели.
Этот стандарт устанавливает порядок присвоения группе станков одинакового класса точности, который должен обеспечивать одинаковую точность обработки идентичных по форме и размеру образцов изделий.
Станки отделочно-расточные вертикальные. Нормы точности – РТС-тендер
ГОСТ 594-82
Группа Г81
МЕЖГОСУДАРСТВЕННЫЙ СТАНДАРТ
ОКП 38 1262
Дата введения 1983-07-01
Постановлением Государственного комитета СССР по стандартам от 9 августа 1982 г. N 3129 дата введения установлена 01.07.83
Ограничение срока действия снято по протоколу N 2-92 Межгосударственного Совета по стандартизации, метрологии и сертификации (ИУС 2-93)
ВЗАМЕН ГОСТ 594-77
ПЕРЕИЗДАНИЕ. Июль 2002 г.
Июль 2002 г.
Настоящий стандарт распространяется на одношпиндельные вертикальные отделочно-расточные станки общего назначения классов точности П и В с фланцевым креплением шпиндельного узла.
1.1. Общие требования к испытаниям на точность – по ГОСТ 8-82.
1.2. Нормы точности станков классов точности П и В не должны превышать значений, указанных в пп.1.3-1.12.
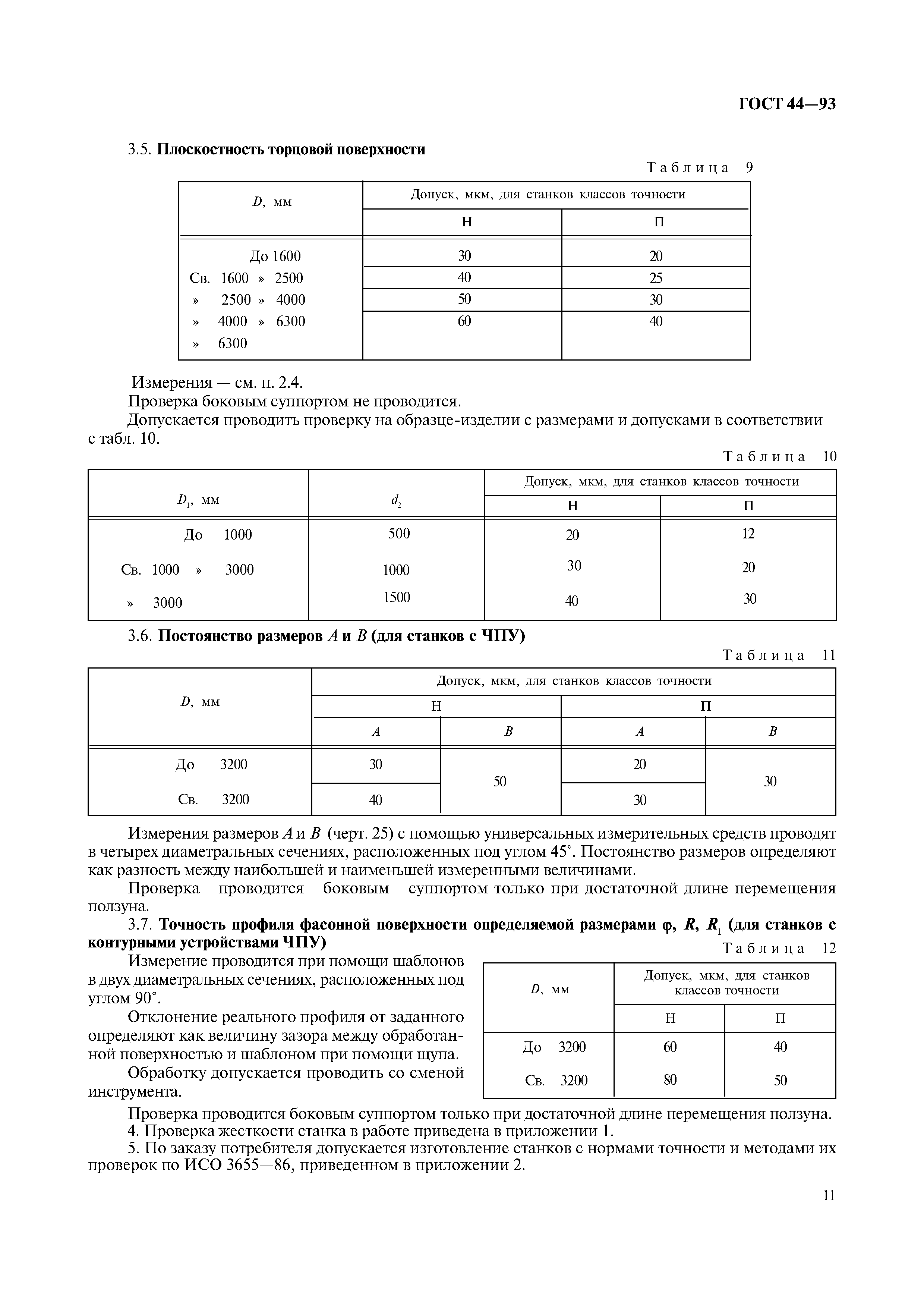
1.3. Плоскостность рабочей поверхности стола (плиты)
Черт.1
Таблица 1
Длина измерения, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 500 | 16 | 12 |
Св. | 20 | 16 |
” 800 ” 1250 | 25 | 20 |
” 1250 ” 2000 | 30 | 25 |
Выпуклость не допускается | ||
 500 до 800
500 до 800Измерения – по ГОСТ 22267-76 (разд.4, метод 3) не менее чем в двух продольных, трех поперечных и двух диагональных сечениях стола (плиты). Крайние сечения должны быть расположены от края стола на расстоянии 0,2 ширины или длины стола (плиты) – см. черт.1.
1.4. Прямолинейность траектории продольного и поперечного перемещений стола в вертикальной и горизонтальной плоскостях (в поперечном направлении для станков с отсчетным устройством на столе)
Черт.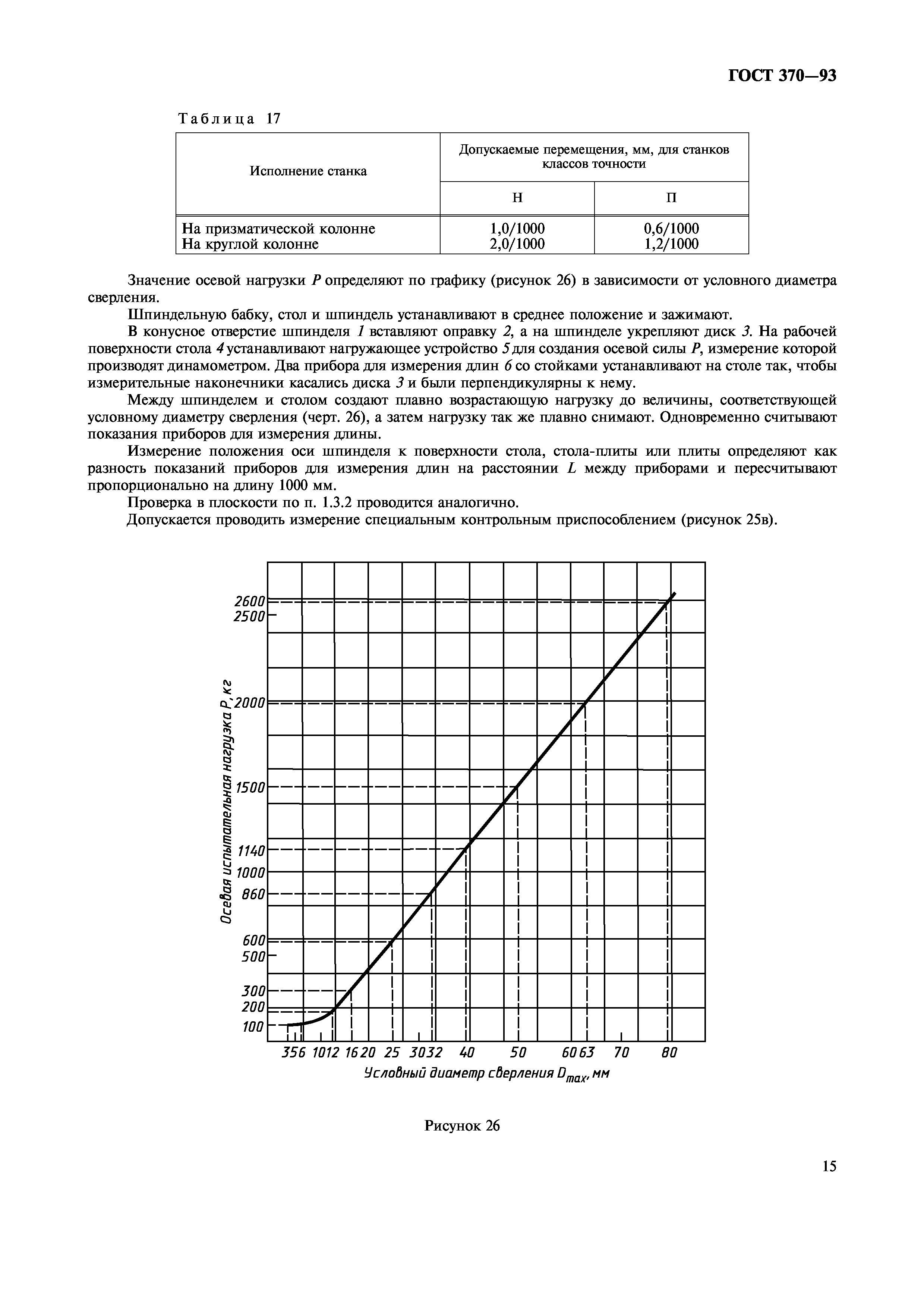 2
2
Таблица 2
Длина перемещения, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 320 | 10 | 8 |
Св. 320 до 500 | 12 | 10 |
” 500 ” 800 | 16 | 12 |
” 800 ” 1250 | 20 | 16 |
Измерения – по ГОСТ 22267-76, разд. 3, метод 1б.
3, метод 1б.
При измерениях стол перемещают на всю длину хода (черт.2).
1.5. Постоянство положения стола в плоскости, перпендикулярной направлению его перемещения
Черт.3
Допуск, мм/м, для станков класса точности:
Измерения – по ГОСТ 22267-76, разд.13, метод 1.
На рабочей поверхности стола 2, в его средней части, перпендикулярно направлению его перемещения устанавливают уровень 1.
Стол перемещают на всю длину хода (черт.3).
Расстояние между точками измерения не должно превышать 0,2 длины хода стола.
Измерения проводят в трех положениях стола в поперечном направлении.
1.6. Параллельность боковых сторон направляющего паза стола траектории перемещения стола
Черт.4
Таблица 3
Длина перемещения, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 500 | 16 | 12 |
Св. | 20 | 16 |
” 800 ” 1250 | 25 | 20 |
 500 до 800
500 до 800На неподвижной части станка укрепляют показывающий измерительный прибор 1 так, чтобы его измерительный наконечник касался проверяемой поверхности (черт.4).
Стол 2 перемещают на всю длину хода, но не более длины паза.
Параллельность измеряют по обеим боковым сторонам направляющего паза стола.
Допускается проводить измерение по контрольной кромке стола.
Отклонение от параллельности траектории перемещения равно наибольшей алгебраической разности показаний показывающего измерительного прибора на всей длине хода.
1.7. Перпендикулярность направления поперечного перемещения стола продольному перемещению (для станков с отсчетным устройством на столе)
Черт. 5
5
Допуск, мкм, для станков класса точности:
Измерения – по ГОСТ 22267-76, разд.8, метод 1.
При измерении стол в продольном направлении устанавливают в среднее положение (черт.5).
1.8. Радиальное биение контрольного пояска шпинделя
Черт.6
Таблица 4
Диаметр фланца шпинделя, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 200 | 6 | 4 |
Св. 200 до 250 | 8 | 5 |
” 250 ” 320 | 10 | 6 |
Измерения – по ГОСТ 22267-76, разд. 15, метод 1 (черт.6).
15, метод 1 (черт.6).
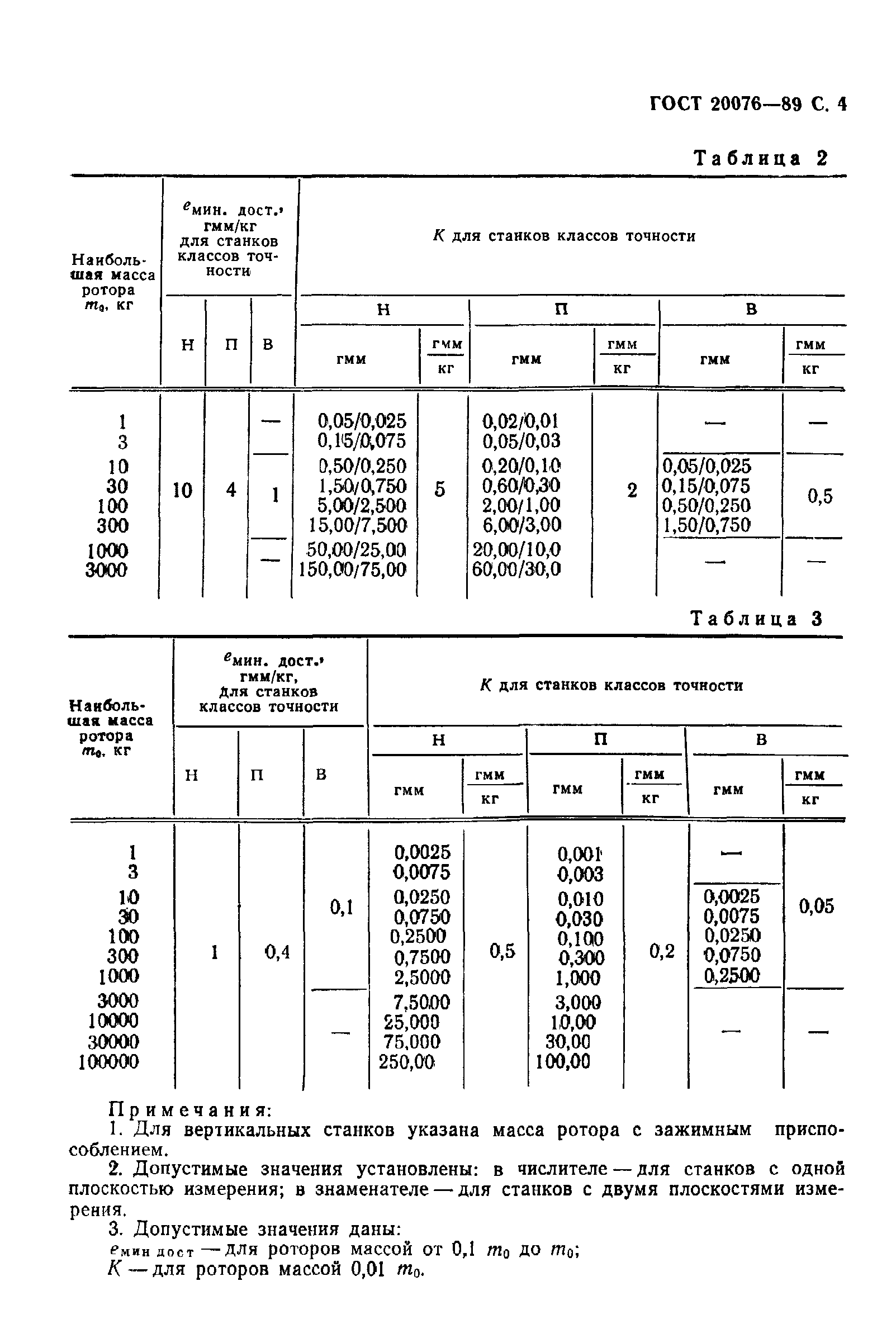
1.9. Радиальное биение внутреннего конуса шпинделя:
а) у торца шпинделя;
б) на расстоянии .
Черт.7
Таблица 5
Диаметр фланца шпинделя, мм | Номер пункта | , мм | Допуск, мкм, для станков класса точности | |
П | В | |||
До 200 | 1.7а | – | 6 | 4 |
1. | 200 | 8 | 5 | |
Св. 200 до 250 | 1.7а | – | 8 | 5 |
1.7б | 300 | 10 | 6 | |
Св. 250 до 320 | 1.7а | – | 10 | 6 |
1.7б | 300 | 12 | 8 | |
 7б
7бИзмерения – по ГОСТ 22267-76, разд. 15, метод 2 (черт.7).
15, метод 2 (черт.7).
1.10. Перпендикулярность оси вращения шпинделя рабочей поверхности стола (плиты) в продольном и поперечном направлениях
Черт.8
Таблица 6
Ширина стола, мм | , мм | Допуск, мкм, для станков класса точности | |
П | В | ||
До 500 | 200 | 16 | 10 |
Св. 500 до 800 | 300 | 20 | 12 |
Измерения – по ГОСТ 22267-76, разд. 10, метод 1.
10, метод 1.
Перед измерением подвижный стол закрепляют в среднем положении.
Измерения проводят в двух крайних положениях шпиндельной бабки по высоте (черт.8).
Допускается проводить измерение по поверочной линейке.
1.11. Перпендикулярность траектории перемещения шпиндельной бабки рабочей поверхности стола (плиты) в продольном и поперечном направлениях
Черт.9
Таблица 7
Длина перемещения, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 320 | 16 | 12 |
Св. | 20 | 16 |
” 500 ” 800 | 25 | 20 |
” 800 ” 1250 | 30 | 25 |
Допускается наклон шпиндельной бабки только к колонне | ||
 320 до 500
320 до 500Измерения – по ГОСТ 22267-76, разд.9, метод 1б (черт.9).
1.12. Точность установки стола по штриховым мерам (для станка с отсчетным устройством на столе)
Черт.10
Таблица 8
Длина перемещения, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 320 | 20 | 12 |
Св. | 25 | 16 |
” 500 ” 800 | 30 | 20 |
” 800 ” 1250 | 40 | 25 |
 320 до 500
320 до 500Измерения – по ГОСТ 22267-76, разд.19, метод 1.
Стол перемещают на длину хода и закрепляют (черт.10).
Измерения проводят с интервалами, равными 0,1 наибольшего перемещения, но не более 100 мм.
Нормы точности образца-изделия для станков классов точности П и В не должны превышать значений, указанных в табл.9, 10 и 12.
Для измерения используют чугунный образец. Отверстия образца должны быть предварительно обработаны. Основание и грани, используемые в качестве измерительных баз, обработаны окончательно.
2.1. Точность цилиндрической внутренней поверхности образца-изделия (черт.11):
а) цилиндричность;
б) круглость
– наибольший диаметр растачиваемого отверстия на станке.
Черт.11
Таблица 9
Наибольший диаметр растачиваемого отверстия образца, мм | Номер пункта | Допуск, мкм, для станков класса точности | |
П | В | ||
До 65 | 2.1а | 8 | 5 |
2. | 3 | 2 | |
Св. 65 до 125 | 2.1а | 10 | 6 |
2.1б | 4 | 2,5 | |
Св. 125 до 250 | 2.1а | 12 | 8 |
2.1б | 5 | 3 | |
 1б
1бКруглость измеряют с помощью кругломера и универсальных средств для измерения диаметров отверстий.
Цилиндричность – с помощью специальных средств для проверки цилиндричности.
Отклонение от круглости равно наибольшему расстоянию от точек реального профиля до прилегающей окружности.
Отклонение от цилиндричности равно наибольшему расстоянию от точек реальной поверхности до прилегающего цилиндра в пределах нормируемого участка.
Допускается вместо цилиндричности проводить измерения постоянства диаметра в любых сечениях.
2.2. Перпендикулярность осей обработанных отверстий образца-изделия измерительной базе основания
Образец – прямоугольный параллелепипед
– наибольший диаметр растачиваемого отверстия на станке
Черт.12
Таблица 10
Длина растачиваемого отверстия образца, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 200 | 12 | 8 |
Св. | 16 | 10 |
” 320 ” 500 | 20 | 12 |
Для станков с подвижным столом допуск увеличивают в 1,25 раза | ||
 200 до 320
200 до 320Образец закрепляют на столе станка и производят чистовую расточку отверстия.
Образец устанавливают боковой гранью на контрольную плиту 2 и с помощью показывающего измерительного прибора 1 измеряют расстояние от плиты до нижней образующей отверстия у обоих торцев (черт.12).
Затем образец поворачивают на другую грань, расположенную под углом 90° к первой, и повторяют указанные измерения.
Отклонение от перпендикулярности равно наибольшей алгебраической разности показаний измерительного прибора в каждой плоскости с учетом конусности обработанного отверстия.
2.3. Точность межосевых расстояний отверстий образца-изделия после чистовой обработки (для станков с отсчетным устройством на столе)
Черт.13
Таблица 11
мм
Ширина стола | ||
До 400 | 150 | 100 |
” 500 | 250 | 150 |
” 630 | 350 | 200 |
Таблица 12
Расстояние между осями отверстий, мм | Допуск, мкм, для станков класса точности | |
П | В | |
До 200 | 25 | 16 |
Св. | 30 | 20 |
” 320 ” 500 | 36 | 22 |
” 500 ” 800 | 40 | 25 |
 200 до 320
200 до 320Измерения проводят с помощью координатно-измерительной машины или оправок, вставляемых в обработанные отверстия (черт.13), и плоскопараллельных концевых мер длины (плиток).
Поле допуска диаметра растачиваемого отверстия образца-изделия не должно превышать Н7 для станков класса точности П и Н6 для станков класса точности В.
Погрешность межосевых расстояний равна разности заданного и фактического расстояний между осями любых двух отверстий.
2.4. Шероховатость обработанной цилиндрической внутренней поверхности образца – см. черт.11.
черт.11.
Параметр шероховатости по ГОСТ 2789-73 для станков класса точности П – 2,5 мкм, класса точности В – 1,25 мкм.
Параметр шероховатости обработанной поверхности измеряют универсальными средствами для контроля шероховатости поверхности.
Точность станка – Энциклопедия по машиностроению XXL
Протягиваемая деталь / закрепляется обычно в разрезной втулке 2 самоцентрирующим трехкулачковым патроном 3. Протяжка 4 закрепляется на суппорте 5 станка, перемещаемого ходовым винтом 6. Точность протягиваемых винтовых шлицев обеспечивается точностью станка. [c.348]Допуски размеров регламентируются ГОСТ 25346—82, допуски формы и расположения — ГОСТ 24643—81. В зависимости от поставленной задачи различают технологическую точность процесса обработки операционную технологическую точность станков и т. д. [c.75]
Выбор контролируемых параметров и их комплексов, а также способов контроля должен обеспечить высокое качество зубчатых передач при минимальных затратах времени на контроль.
 Непосредственный контроль зубчатых колес и передач по отдельным показателям увеличивает число контрольных операций п требует проверки всех изготовляемых зубчатых колес. Гораздо выгоднее в техническом и экономическом отношении применять профилактический контроль, при котором точность обработки зубчатых колес обеспечивается соответствующей организацией технологических процессов их изготовления, т. е. точностью станков, приспособлений, режущего инструмента, а также систематическим наблюдением за состоянием технологической оснастки и другими мерами.
[c.208]
Непосредственный контроль зубчатых колес и передач по отдельным показателям увеличивает число контрольных операций п требует проверки всех изготовляемых зубчатых колес. Гораздо выгоднее в техническом и экономическом отношении применять профилактический контроль, при котором точность обработки зубчатых колес обеспечивается соответствующей организацией технологических процессов их изготовления, т. е. точностью станков, приспособлений, режущего инструмента, а также систематическим наблюдением за состоянием технологической оснастки и другими мерами.
[c.208]Согласно п. 2.8. ГОСТ 1643—72 непосредственный контроль зубчатых колес не является обязательным, если изготовитель существующей у него системой контроля точности производства гарантирует выполнение соответствующих требований стандарта. В этом случае изготовитель должен установить комплекс показателей точности выпускаемой им продукции, который является арбитражным. Кроме него могут быть установлены дополнительные показатели точности, контролируемые в процессе изготовления зубчатых колес (текущий контроль) и при их приемке (приемочный). Эти показатели могут отличаться от предусмотренных ГОСТ 1643—72, но совместно с объектами профилактического контроля (точности станков, инструментов, приспособлений и заготовок) должны обеспечить выполнение требований стандарта по принятому изготовителем арбитражному комплексу.
[c.693]
Эти показатели могут отличаться от предусмотренных ГОСТ 1643—72, но совместно с объектами профилактического контроля (точности станков, инструментов, приспособлений и заготовок) должны обеспечить выполнение требований стандарта по принятому изготовителем арбитражному комплексу.
[c.693]
Деформация деталей может происходить и при напряжениях, находящихся в пределах упругости за счет перераспределения внутренних напряжений. Эти напряжения могут возникнуть в процессе отливки детали или при структурных превращениях. Так, коробление станин и других корпусных деталей станков может повлиять на точность станка, если не принять специальных методов обработки. [c.85]
Например, известно, что точность обработки на станке должна находиться в пределах 0,05 мм, т. е. допустимая погрешность шах = од Надо ли восстанавливать точность станка, если [c.175]
На начальные параметры точности станка влияет геометрическая точность изготовления и сборки его узлов, жесткость и виброустойчивость системы, а также ее тепловые деформации. В стадии проектирования эти показатели должны быть регламентированы соответствующими нормативами, а при наличии” опытного образца подтверждены его испытанием. Погрешности обработки, вызванные перечисленными факторами, определяют запас надежности, т. е. ту часть допуска на обработку, которая будет не израсходована и оставлена в качестве запаса на износ. Хотя оценка начальных параметров машины на стадии ее проектирования является сложной самостоятельной проблемой, она не несет в себе опасности эксплуатации некачественной машины, поскольку неточность предварительной оценки начальных показателей проявится сразу же при испытании первого образца. После этого можно внести исправления в серийную модель или в данный образец. Вместе с тем прогнозирование потери точности от износа имеет большое значение потому, что результат износа проявится лишь после достаточно длительного периода эксплуатации машины.
[c.371]
В стадии проектирования эти показатели должны быть регламентированы соответствующими нормативами, а при наличии” опытного образца подтверждены его испытанием. Погрешности обработки, вызванные перечисленными факторами, определяют запас надежности, т. е. ту часть допуска на обработку, которая будет не израсходована и оставлена в качестве запаса на износ. Хотя оценка начальных параметров машины на стадии ее проектирования является сложной самостоятельной проблемой, она не несет в себе опасности эксплуатации некачественной машины, поскольку неточность предварительной оценки начальных показателей проявится сразу же при испытании первого образца. После этого можно внести исправления в серийную модель или в данный образец. Вместе с тем прогнозирование потери точности от износа имеет большое значение потому, что результат износа проявится лишь после достаточно длительного периода эксплуатации машины.
[c.371]
Прогнозирование потери точности обработки при износе сопряжений станка.
 Для прогнозирования потери точности станком применительно к параметру X = A построим зависимость по рассмотренной в гл. 3, п. 1 методике. При постоянной скорости изнашивания U = yt зависимость (8) также будет линейной во времени
[c.376]
Для прогнозирования потери точности станком применительно к параметру X = A построим зависимость по рассмотренной в гл. 3, п. 1 методике. При постоянной скорости изнашивания U = yt зависимость (8) также будет линейной во времени
[c.376]Допуск на обработку дна кармана по техническим условиям (2-й класс точности) равен б == 27 мкм. Погрешности, связанные с начальной точностью станка, его температурными деформациями, жесткостью, износом инструмента, точностью приспособлений и другими факторами, по проведенным исследованиям [193] доходят до 20 мкм. Следовательно, запас на износ составляет Д [c.376]
Блок-схема алгоритма управления точностью обработки, реализуемого с помощью вычислительного устройства, начинается с ввода исходных данных, представляющих собой константы и вспомогательные параметры, не изменяющиеся во времени. Исходная информация дополняется текущей информацией от датчиков, регистрирующих состояние рабочих органов станка в тот или иной момент времени. На основании поступившей информации вычисляются зона рассеивания от быстропротекающих процессов, зона рассеивания погрешностей настройки, а также другие параметры, характеризующие точность станка. Далее определяются текущие верхняя и нижняя границы возможного смещения уровня настройки и фактическое на данный момент времени ее значение.
[c.467]
На основании поступившей информации вычисляются зона рассеивания от быстропротекающих процессов, зона рассеивания погрешностей настройки, а также другие параметры, характеризующие точность станка. Далее определяются текущие верхняя и нижняя границы возможного смещения уровня настройки и фактическое на данный момент времени ее значение.
[c.467]
Для получения равномерного слоя на рабочих поверхностях зубьев и во впадине, последняя должна изготавливаться с высокой степенью точности. Станок, на котором производится закалка, должен обеспечивать высокую точность взаимного расположения индуктора и закаливаемой поверхности. Допуск на это расположение не должен превышать половины зазора. Такой допуск обеспечить довольно трудно. [c.164]
В поддержании стабильности технологических процессов наиболее действенными мероприятиями оказались сведение к минимуму влияния субъективных факторов на ход производства путем его механизация и автоматизации внедрение статистических методов регулирования технологических процессов и контроля поддержание требуемой технологической точности станков и оснастки поддержание высокой технологической дисциплины.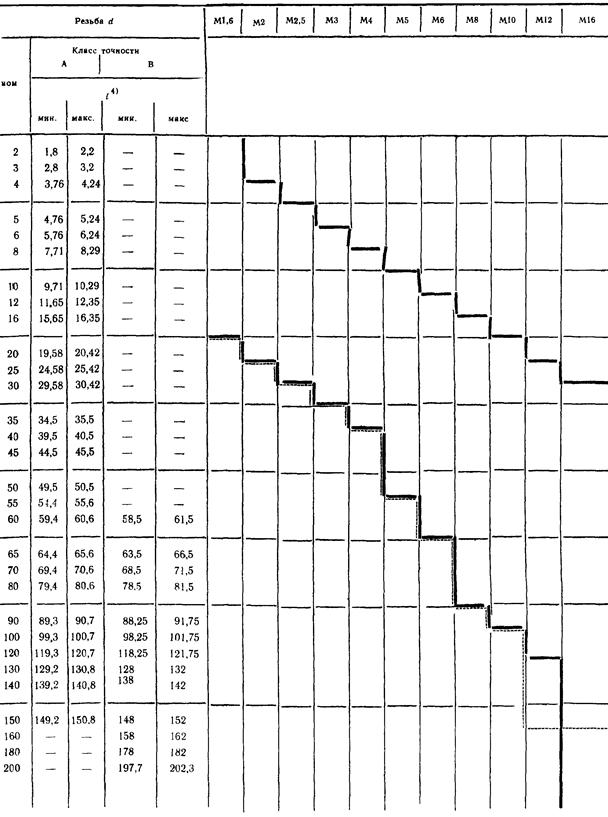 [c.218]
[c.218]
Эта же лаборатория по графику, утвержденному главным инженером завода, ведет систематический контроль точности чистовых станков и технологической оснастки. При обнаружении потери точности станки и оснастку из эксплуатации выводят и передают в ремонт. [c.240]
В связи с вопросами, рассмотренными в следующей главе, представляют интерес решения на основании вероятностной информации, причем та особая разновидность таких решений, при которой информация представляет собой результат выборочной проверки. Термин выборочная проверка в данном случае толкуется широко и охватывает не только собственно выборочные проверки (вроде выборочного контроля годности партии продукции), но и статистические исследования, например точности станка, наблюдения облачности в метеорологии и пр. Все такого рода способы получить информацию для решения обладают тем общим свойством, что они являются проверками объективных условий применительно к которым выбирается тот или иной образ действий (иначе говоря, выбирается решение).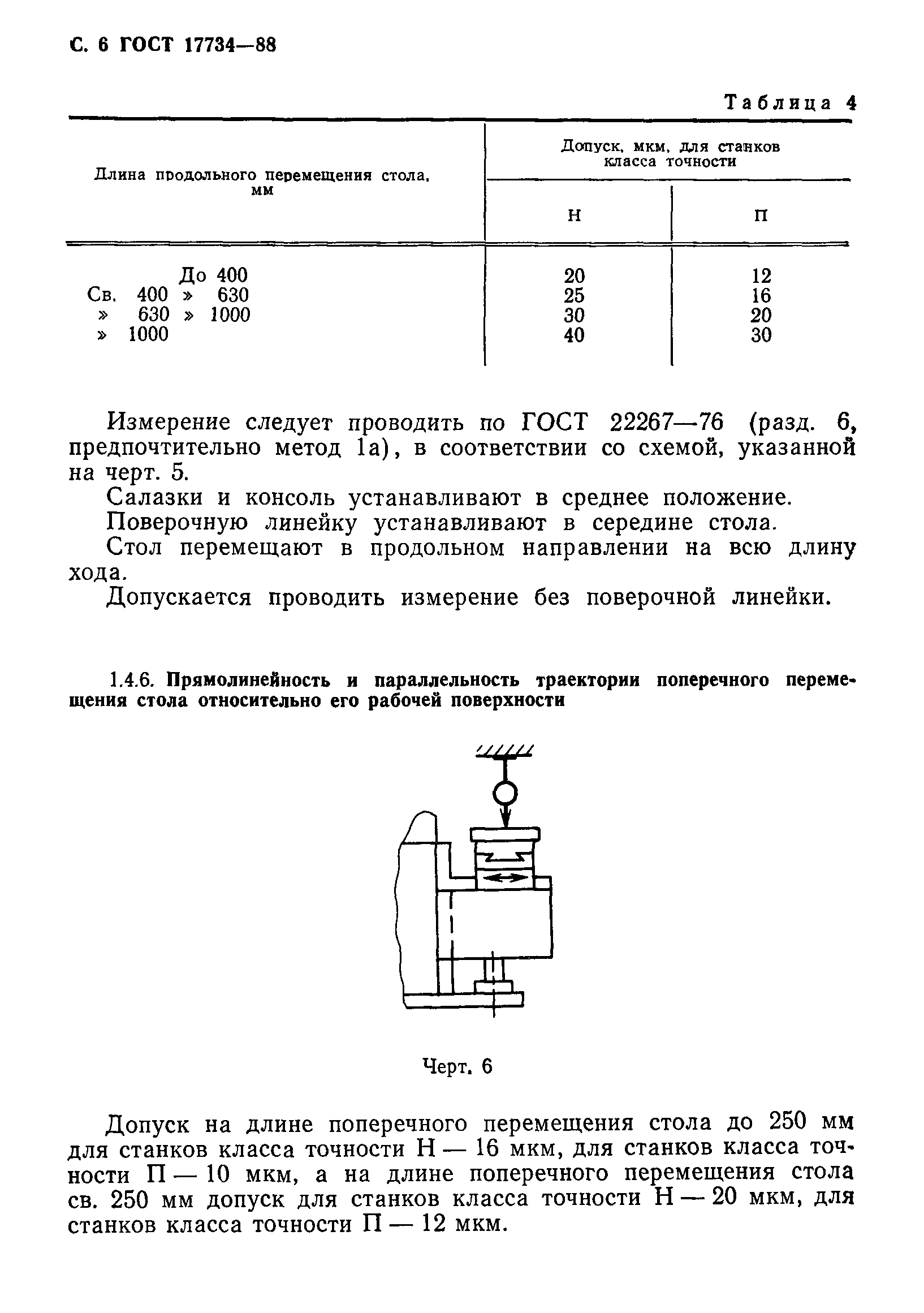 Характерными примерами такого рода выборочных проверок являются
[c.21]
Характерными примерами такого рода выборочных проверок являются
[c.21]
Таким образом, испытание станков на точность производят измерением геометрических точностей станка, а также определением точности обработки изделия. [c.625]
К неуправляемым относятся параметры деталей, заданная точность которых обеспечивается настройкой станка, не подвергающейся текущему корректированию к ним относятся в основном отклонения формы и взаимного расположения поверхностей. При снижении точности станок останавливают для наладки или ремонта. Эта операция нарушает ритм автоматической работы и снижает производительность АЛ. Поэтому одно из главных требований к автоматическим процессам обработки заключается в том, чтобы настройка станка, обеспечивающая заданную точность, особенно неуправляемых параметров, сохранялась на протяжении достаточно длительного времени. [c.94]
При эксплуатации станков вследствие износа деталей и других медленно протекающих процессов центр группирования размеров постепенно смещается и одновременно увеличивается поле рассеяния размеров в результате действия быстропротекающих процессов. При этом постепенно исчерпывается запас точности станка. [c.386]
Точность применяемого оборудования и технологической оснастки оказывает решающее влияние на точность и стабильность технологического процесса и, в конечном счете, на качество выпускаемой продукции. На точность станка влияют различные факторы — совершенство конструкции и качество ее исполнения, период сохранения первоначальной точности, качество эксплуатации и ремонта и др. [c.78]
Проблема повышения точности станков поставила задачу четкой фиксации положения их движущихся узлов. [c.79]
Кривая 1 на рис. 35 определена по предварительным статистическим данным и приближенно выражает общий характер потерь точности во времени А — поле рассеяния кривой 2, отражающей изменение первоначальной точности станка. [c.161]
Потеря точности станка П-ц. может быть выражена следующей зависимостью [c.161]
Шпиндельная головка также является местом выделения большого количества тепла. Изменение положения оси шпинделя при температурных деформациях решающим образом влияет на потерю точности станка. [c.187]
Впервые в Советском Союзе в 1965 г. завод освоил выпуск тяжелых расточных станков с диаметром шпинделя до 250 мм и с программным управлением. Это станки-ис-полины, каждый из которых весит около 270 т. Такой горизонтально-расточный станок может обрабатывать детали весом 200—250 т. Точность станка 0,03 мм, что в 3 ра- [c.95]
В единичном и мелкосерийном производстве заготовки имеют обычно большие припуски на обработку, и время для черновых операций доходит до 50% общего времени обработки. Как правило, в указанных производствах нет деления на черновые и чистовые операции, в результате быстро теряется производительность и точность станков, происходит их ускоренный износ, нерационально используются на обдирочных операциях квалифицированные рабочие. [c.235]
Группирование по точности и сложности обработки позволяет обрабатывать детали на оптимальных режимах в зависимости от требуемой точности и сложности операций, сохранять точность станков длительное время, рационально использовать высококвалифицированных рабочих, резко сократить номенклатуру инструмента, используемого на рабочих местах. [c.235]
Для применения в механических цехах станков с ЧПУ осуществляются мероприятия по совершенствованию технологии, подготовки к разметке заготовок. Особенно тщательно разрабатываются процессы изготовления базовых и корпусных деталей, поскольку у большинства машин (особенно металлорежущих станков) указанные детали определяют выходные параметры и конечную точность станков. Например, литые и сварные заготовки базовых и корпусных деталей до подачи в механический цех должны пройти обрубку и очистку, подгонку контуров сопрягаемых деталей, грунтовку и окраску. [c.308]
При других методах измерения эти ошибки могут быть значительными. Так, при прямом бесконтактном методе фактический размер детали часто определяется путем измерения величины зазора (например, с помощью фотоэлемента) между поверхностью детали и измерительной базой контрольного устройства. Фиксированная величина этого зазора будет определяться при этом не только положением поверхности детали по отношению к измерительной базе, но и другими, случайно появляющимися факторами. Фиксированная величина зазора может уменьшаться, если поверхность детали покрыта пленкой смазывающе-охлаждающей жидкости или если в зазор попадают абразивная пыль, мелкая стружка, что весьма характерно для шлифовальных операций. При косвенных методах измерения, когда об изменении размера детали судят по перемещению частей станка или режущего инструмента, на точность контроля оказывают влияние такие факторы, как жесткость элементов, технологической системы, точность станка и износ режущего инструмента. [c.94]
Практически достижимая точность станков с числовым программным управлением зависит главным образом от качества выполнения и надежности всех элементов системы управления, от точности и жесткости механизмов станка. [c.157]
Не разбирая подробно вопросов проверки на геометрическую точность, отметим одно обстоятельство, имеющее значение и при монтаже станков при контроле точности станка необходимо учитывать величину собственного прогиба оправок. Величина [c.417]
Изменение температурного состояния в узлах прецизионных станков от тепловыделений в кинематических парах в процессе их работы приводит к потере первоначальной точности станков. Для автоматической компенсации температурных смещений целесообразно при проектировании указанных станков предусматривать специальные системы регулирования и устройства. При решении этого вопроса необходимо иметь сведения о законах распределения температур в узлах. [c.415]
Экспериментами было установлено, что система отрабатывает рассогласование практически независимо от величины и характера изменения исходной погрешности обработки А , материала и размеров детали, глубины резания и продольной геометрической точности станка. При этом погрешность Ар г составляет около 3—5 мкм. Др . значительно возрастает при прерывистом включении системы в работу. [c.359]
Испытания станка на холостом ходу и с нагрузкой, проверка точности станка и сдача техническому контролю должны производиться непосредственно на рабочем месте или на испытательном стенде. [c.177]
Проверка точности (до разборки) Проверка точности станка по нормам ГОСТа с целью установления отклонений от норм. Проверка положения оборудования на фундаменте. Составление плана-графика выполнения работы [c.203]
Точность станка определяют измерением его геометрических точностей и точности обработки образцов. Станок при этом устанавливают и выверяют на фундаменте на стальных клиньях. [c.609]
Точность станка в ненагруженном состоянии, называемая геометрической точностью станка, зависит главным образом от точности изготовления основных деталей и узлов станка и точности их сборки. Погрешности, допущенные в размерах и форме этих деталей и их взаимном расположении (плсскостность, цилиндрич-ность, параллельность и перпендикулярность осей и плоскостей, концентричность, соосность и т. д.), называют иногда геометрическими погрешностями станка. [c.48]
Расчет влияния износа сопряжений на точность станка. 1-ассмотрим влияние износа сопряжений на точность станка на примере образования погрешности дна кармана при обработке фасонного профиля в режиме копирования. Погрешность обра-Готки в случае увеличения диаметра обработанного отверстия будем считать а при его уменьшении -г-А (рис. 122, й). [c.372]
Работами ЭНИМСа, Укроргстанкинпрома, Вильнюсского завода шлифовальных станков и Минского станкозавода им. Кирова определена возможность изготовления из стеклопластиков крупногабаритных деталей металлорежущих станков. Четырехлетняя эксплуатация в цеховых условиях завода Станкоконструкция двух токарно-винторезных станков модели IK62, у которых методом контактного формования из стеклопластиков были изготовлены передняя и задняя ножки, крышки коробок скоростей и подач и другие крупногабаритные детали, показала, что замена металла пластмассой не нарушила точности станка. [c.220]
Стабильность качества обеспечивается повышением стабильности технологических процессов производства путем соблюдения качества исходных материалов и заготовок, поддержанием технологической точности станков и оснастки, использованием системы бездефектного изготовления продукции, непрерывным повышением уровня научной организации труда, соблюдением технологической дисциплины, повышением уровня технической подготовки производственного персонала, обеспечиванием надежности, эффективности средств и методов контроля, поддержанием единства мер. [c.231]
Второе решение обладает еще одним преимуществом при потере точности станка для восстановления ее при первом варианте необходим ремонт, тогда как при втором решении потребуется только подрегулирование. Применение подвижных компенсаторов исключает в ряде случаев надобность в пригонке базовых поверхностей деталей при сборке. [c.655]
Для улучшения использования станков заготовки закрепляют в быстро переналаживаемых (УНП) или универсальносбор-Бых (УСП) приспособлениях. Система управления с программированием цикла и режимов обработки применяется на многих станках токарной группы, например, на многорезцовом гидро-фицированном полуавтомате мод. АТ250П Савеловского машиностроительного завода (г. Кимры). Полуавтомат предназначен для обработки деталей диаметром до 250 мм типа дисков, фланцев, шестерен, муфт и т. п. по 2—3-му классам точности. Станок оснащен двумя суппортами, каждый из которых имеет независимую продольную и поперечную подачи. Величина перемещений устанавливается по линейкам и упорам при наладке станка на обработку очередной партии деталей. Последовательность [c.141]
|
Станки |
Группа |
Тип |
Назначение станка |
|
ТОКАРНЫЕ |
1 |
0 |
автоматы и полуавтоматы специализированные |
|
1 |
автоматы и полуавтоматы одношпиндельные | ||
|
2 |
автоматы и полуавтоматы многошпиндельные | ||
|
3 |
токарно-револьверные | ||
|
4 |
токарно-револьверные полуавтоматы | ||
|
5 |
карусельные | ||
|
6 |
токарные и лоботокарные | ||
|
7 |
многорезцовые и копировальные | ||
|
8 |
специализированные | ||
|
9 |
разные токарные | ||
|
СВЕРЛИЛЬНЫЕ И РАСТОЧНЫЕ |
2 |
0 |
– |
|
1 |
настольно- и вертикально-сверлильные | ||
|
2 |
полуавтоматы одношпиндельные | ||
|
3 |
полуавтоматы многошпиндельные | ||
|
4 |
координатно-расточные | ||
|
5 |
радиально- и координатно-сверлильные | ||
|
6 |
расточные | ||
|
7 |
отделочно-расточные | ||
|
8 |
горизонтально-сверлильные | ||
|
9 |
разные сверлильные | ||
|
ШЛИФОВАЛЬНЫЕ, |
3 |
0 |
– |
|
1 |
круглошлифовальные, бесцентрово-шлифовальные | ||
|
2 |
внутришлифовальные, координатно-шлифовальные | ||
|
3 |
обдирочно-шлифлвальные | ||
|
4 |
специализированные шлифовальные | ||
|
5 |
продольно-шлифовальные | ||
|
6 |
заточные | ||
|
7 |
плоско-шлифовальные | ||
|
8 |
притирочные,
полировальные,хонинговальные, | ||
|
9 |
разные станки, работающие абразивом | ||
|
ЭЛЕКТРОФИЗИЧЕСКИЕ, |
4 |
0 |
– |
|
1 |
– | ||
|
2 |
светолучевые | ||
|
3 |
– | ||
|
4 |
электрохимические | ||
|
5 |
– | ||
|
6 |
– | ||
|
7 |
электроэрозионные, ультразвуковые прошивочные | ||
|
8 |
анодно-механические отрезные | ||
|
9 |
– | ||
|
ЗУБО- и |
5 |
0 |
резьбонарезные |
|
1 |
зубодолбежные для цилиндрических колес | ||
|
2 |
зуборезные для конических колес | ||
|
3 |
зубофрезерные для
цилиндрических колес | ||
|
4 |
для нарезания червячных колес | ||
|
5 |
для обработки торцов зубьев колес | ||
|
6 |
резьбо-фрезерные | ||
|
7 |
зубоотделочные, проверочные и обкатные | ||
|
8 |
зубо- и резьбо-шлифовальные | ||
|
9 |
разные зубо- и резьбообрабатывающие | ||
|
ФРЕЗЕРНЫЕ |
6 |
0 |
барабано-фрезерные |
|
1 |
вертикально-фрезерные консольные | ||
|
2 |
фрезерные непрерывного действия | ||
|
3 |
продольные одностоечные | ||
|
4 |
копировальные и гравировальные | ||
|
5 |
вертикально-фрезерные бесконсольные | ||
|
6 |
продольные двухстоечные | ||
|
7 |
консольно-фрезерные операционные | ||
|
8 |
горизонтально-фрезерные консольные | ||
|
9 |
разные фрезерные | ||
|
СТРОГАЛЬНЫЕ, |
7 |
0 |
– |
|
1 |
продольные одностоечные | ||
|
2 |
продольные двухстоечные | ||
|
3 |
поперечно-строгальные | ||
|
4 |
долбежные | ||
|
5 |
протяжные горизонтальные | ||
|
6 |
протяжные
вертикальные для протягивания | ||
|
7 |
протяжные
вертикальные для протягивания | ||
|
8 |
– | ||
|
9 |
разные строгальные станки | ||
|
РАЗРЕЗНЫЕ |
8 |
0 |
– |
|
1 |
отрезные, работающие резцом | ||
|
2 |
отрезные, работающие абразивным кругом | ||
|
3 |
гладким или насечным диском | ||
|
4 |
правильно-отрезные | ||
|
5 |
ленточно-пильные | ||
|
6 |
отрезные с дисковой пилой | ||
|
7 |
отрезные ножовочные | ||
|
8 |
– | ||
|
9 |
– | ||
|
РАЗНЫЕ |
9 |
0 |
– |
|
1 |
трубо- и муфтообрабатывающие | ||
|
2 |
пилонасекательные | ||
|
3 |
правильно- и бесцентровообдирочные | ||
|
4 |
– | ||
|
5 |
для испытания инструментов | ||
|
6 |
делительные машины | ||
|
7 |
балансировочные | ||
|
8 |
– | ||
|
9 |
– |
Соответствие средств измерения классу точности станка – Ремонт и восстановление станков (общие вопросы)
“Зачем вам квалитеты? В нормах точности даны конкретные значения допусков.”
Поскольку длины измеряемых поверхностей и измерительного инструмента разные, я пытаюсь привести их к какому-то понятному, для себя, значению.
Например:
В том госте, который Вы мне дали (ГОСТ 8-82) на 11 странице имеется пример пересчета допусков при изменении длины измерения.
В моём случае имеем линейку 1кл. Погрешность измерений 10 мкм на 1000 мм. Это примерно соответствует 1 квалитету по таблице квалитетов http://www.gk-drawin…es/qualitas.php.
Имеем так же “основной вертикальный стол” размеры длина 500 ширина 200. По нормам точности ГОСТ 26016-83 Станки фрезерные широкоуниверсальные инструментальные. Нормы точности плоскостность этого стола не должна превышать 10 мкм. на длине 400…630.
Что соответствует 2 квалитету. Теперь находим допуск на длине 400…630 для линейки(которая как мы выяснили соответствует 1 квалитету.)
Получается 8-9 мкм.
Дальше мысль начинает стремительно останавливаться 🙂
Обращаемся опять к госту 8-82 п.3.2. В таблице указано, что допустимые отклонения на допуск при измерениях не должны превышать 25% от этого допуска. Т.е 10мкм*25% / 100 = 2,5 мкм. 10 + 2.5 = 12,5
В результате, что? Можем использовать линейку с погрешностью 12,5 мкм на 400…600? Это соответствует примерно 2 квалитету(с хорошим запасом). Переводим на длину 1000 получаем 15 мкм. Что соответствует линейке 2 класса точности.
Всё правильно? Укажите пожалуйста на ошибки в расчетах.
Сейчас только начал разбираться со всем этим. Отсюда столько сомнений и вопросов.
P.S. Ёлки а для плиты поверочной, по этим расчетам даже 1 класс точности не пойдёт. У неё 16 мкм допуск на размер 630х400.
Нужен 0 класс, получается? Там 8 мкм. на размер 630х400.
Всё… Совсем запутался 🙂 И это только для одного измерения…
Изменено пользователем Горьков_АндрейКлассы точности станков
На каждом виде станков проводится испытание на соответствие норме точности. Результаты испытания записываются в акт, который вкладывается в паспорт станка. Каждый тип станков имеет ГОСТ, который регламентирует допустимые отклонения во всех проверках. Количество проверок для разных типов станков бывает различным. Некоторые модели настольных широкоуниверсальных фрезерных станков с ЧПУ имеют несколько десятков проверок. Все станки классифицируются по точности работы делением на классы:
Допустимые отклонения по проверкам соседних классов точности станков отличаются друг от друга в 1,6 раза. Вот таблица величин допускаемых отклонений при прямолинейном движении для станков, имеющих различный класс точности.
ГОСТ 8-82 для всех видов металлорежущих станков, в том числе и настольных с ЧПУ, устанавливает стандарт общих требований к испытаниям на точность. По нему точность всех станков этого типа определяется по трем группам показателей:
Этот стандарт устанавливает порядок присвоения группе станков одинакового класса точности, который должен обеспечивать одинаковую точность обработки идентичных по форме и размеру образцов изделий.
Повышение точности ваших моделей машинного обучения | от Prashant GuptaУстали от низкой точности моделей машинного обучения? Повышение здесь, чтобы помочь. Boosting – это популярный алгоритм машинного обучения, который повышает точность вашей модели, – то же самое, когда гонщики используют закись азота для увеличения скорости своего автомобиля.
Повышение использует алгоритм базового машинного обучения для подгонки данных. Это может быть любой алгоритм, но дерево решений используется наиболее широко.Для ответа на вопрос, почему так, просто продолжайте читать. Кроме того, алгоритм повышения легко объяснить с помощью деревьев решений, и это будет темой этой статьи. Он основан на подходах, отличных от бустинга, которые повышают точность деревьев решений. Для введения в древовидные методы, прочитайте мою другую статью здесь .
Bootstrapping
Я хотел бы начать с объяснения важного базового метода Bootstrapping .Предположим, что нам нужно изучить дерево решений, чтобы предсказать цену дома на основе 100 входных данных. Точность прогнозирования такого дерева решений будет низкой, учитывая проблему дисперсии , от которой оно страдает. Это означает, что если мы разделим обучающие данные на две части случайным образом и подгоним дерево решений по обеим половинкам, результаты, которые мы можем получить, могут быть совершенно разными. То, что мы действительно хотим, это результат, который имеет низкую дисперсию, если применяется неоднократно к отдельным наборам данных..
Процедура может использоваться аналогичным образом для деревьев классификации . Например, если бы у нас было 5 деревьев решений, которые делали следующие предсказания класса для входной выборки: синий, синий, красный, синий и красный, мы бы выбрали наиболее частый класс и предсказали синий.
При таком подходе деревья глубоко растут и не обрезаются . Таким образом, каждое отдельное дерево имеет высокую дисперсию, но низкое смещение. Усреднение этих деревьев значительно уменьшает дисперсию.
Самозагрузка – это мощный статистический метод оценки количества из выборки данных . Количество может быть описательной статистикой, такой как среднее значение или стандартное отклонение. Применение процедуры начальной загрузки к алгоритму машинного обучения с высокой дисперсией, обычно деревьям решений, как показано в приведенном выше примере, известно как пакетирование (или агрегация начальной загрузки).
Оценка ошибокПростой способ оценки ошибки тестирования модели в пакетах без необходимости перекрестной проверки – Оценка ошибок вне пакета .Наблюдения, которые не использовались для подгонки к данному дереву в мешках, называются наблюдениями из-за-мешка (OOB). Мы можем просто предсказать ответ для и -го наблюдения, используя каждое из деревьев, в которых это наблюдение было OOB. Мы усредняем эти предсказанные ответы или принимаем большинство голосов в зависимости от того, является ли ответ количественным или качественным. Можно рассчитать общий OOB MSE (среднеквадратическая ошибка) или коэффициент ошибки классификации. Это приемлемый коэффициент ошибок при тестировании, потому что прогнозы основаны только на деревьях, которые не были подогнаны с использованием этого наблюдения.
Случайные леса
Деревья решений стремятся минимизировать затраты, а это означает, что они используют самые сильные предикторы / классификаторы для разделения ветвей. Итак, большинство деревьев, созданных из загруженных выборок, будут использовать один и тот же сильный предиктор в разных расщеплениях. Это относится к деревьям и приводит к дисперсии .
Мы можем повысить точность прогнозирования деревьев в мешках, используя случайные леса.
. При разделении ветвей любого дерева в качестве кандидатов-кандидатов выбирается случайная выборка из м предикторов из полного набора p предикторов.Разделение затем разрешается использовать только один из этих м предикторов. Свежая выборка из м предикторов берется при каждом разделении. Вы можете попробовать разные значения и настроить их с помощью перекрестной проверки.
- Для классификации хорошим значением по умолчанию является: m = sqrt (p)
- Для регрессии хорошим значением по умолчанию является: m = p / 3
Таким образом, в среднем ( p – m ) / p расколов даже не будут считать сильным предиктором. Это известно как декоррелирование деревьев, поскольку мы решаем проблему каждого дерева, используя один и тот же сильный предиктор.
Если м = р , то случайные леса равны сумке.
Важность функции
Одна из проблем при вычислении полностью выращенных деревьев состоит в том, что мы не можем легко интерпретировать результаты. И уже не ясно, какие переменные важны для отношений. Расчет падения функции ошибки для переменной в каждой точке разделения дает нам представление о важности функции . Это означает, что мы записываем общую сумму, на которую ошибка уменьшается из-за разбиений по данному предиктору, усредненная по всем деревьям в мешках.Большое значение тогда указывает на важный предиктор. В задачах регрессии это может быть уменьшение остаточной суммы квадратов, а в классификации это может быть оценка Джини.
Повышение
Точность прогнозирования деревьев решений может быть дополнительно улучшена с помощью алгоритмов повышения.
Основная идея повышения – преобразование многих слабых учеников в одного сильного ученика. Что мы подразумеваем под слабыми учениками?
Слабый ученик – это ученик, который всегда добивается большего успеха, чем случайный, когда он пытается маркировать данные, независимо от того, как распределены данные обучения.Успех лучше, чем случайность, означает, что у нас всегда будет уровень ошибок менее 1/2. Это означает, что алгоритм ученика всегда собирается что-то изучать и не всегда будет полностью точным, т. Е. Слабым и плохим, когда речь идет об изучении взаимосвязей между входными данными и целью. Это также означает, что правило, сформированное с использованием одного предиктора / классификатора, не является мощным по отдельности.
Мы начинаем находить слабых учеников в наборе данных, делая некоторые распределения и формируя из них небольшие деревья решений.Размер дерева настраивается с использованием количества расщеплений, которые оно имеет. Часто хорошо работает 1, где каждое дерево состоит из одного разбиения. Такие деревья известны как пней решений.
Другим повышением параметра является число итераций или количество деревьев в этом случае. Кроме того, он присваивает входные значения на основе того, были ли они правильно спрогнозированы / классифицированы или нет. Давайте посмотрим на алгоритм.
- Сначала входы инициализируются равными весами .Для этого используется первый базовый алгоритм обучения, который обычно является пнем решения. Это означает, что на первом этапе это будет слабый ученик, который подберет подвыборку данных и сделает прогнозы для всех данных.
- Теперь мы выполняем следующие до достижения максимального числа деревьев :
- Обновляем веса входных данных на основе предыдущего прогона, и весовые коэффициенты выше для ошибочно прогнозируемых / классифицированных входных данных
- Создайте другое правило (решение о этот случай) и подгонять его под подвыборку данных.Обратите внимание, что это правило времени будет сформировано с учетом неправильно классифицированных входных данных (имеющих больший вес).
- Наконец, мы прогнозируем / классифицируем все входные данные, используя это правило.
3. После завершения итераций мы объединяем слабые правила в единое строгое правило , которое затем будет использоваться в качестве нашей модели.
Приведенный выше алгоритм лучше объясняется с помощью диаграммы. Предположим, у нас есть 10 входных наблюдений, которые мы хотим классифицировать как «+» или «-».
Источник изображения: Analytics Vidhya- Алгоритм повышения начинается с поля 1, как показано выше. Он назначает равные веса (обозначенные размером знаков) для всех входных данных и прогнозирует «+» для входных данных в синей области и «-» для входных данных в красноватой области, используя пень решения D1.
- На следующей итерации, вставке 2, вы увидите, что веса неправильно классифицированных знаков плюс больше, чем другие входные данные. Таким образом, пень решения D2 выбран так, что эти наблюдения теперь классифицируются правильно.
- В заключительной итерации, вставке 3, в ней есть 3 неправильно классифицированных негатива из предыдущего прогона. Таким образом, пень решения D3 выбран, чтобы исправить это.
- Наконец, сильный ученик или вставка 3 имеют строгое правило, объединяющее отдельные слабые решения. Вы можете увидеть, как мы увеличили классификацию нашей модели.
В настройках регрессии ошибка прогнозирования (обычно рассчитывается с использованием метода наименьших квадратов) используется для корректировки весов входных данных, и учащиеся, как следствие, больше внимания уделяют входным данным с большой ошибкой.
Этот тип метода повышения известен как адаптивное повышение или AdaBoost. Как и в случае с деревьями, метод повышения также минимизирует функцию потерь. В случае Adaboost это функция экспоненциальной потери .
Другой популярной версией повышения является алгоритм повышения градиента . Основная концепция остается той же: , за исключением того, что здесь мы не играем с весами, но соответствуют модели по остаткам (измерение разницы в прогнозировании и исходном результате), а не в исходных результатах. Adaboost реализован с использованием итеративно уточненных весов выборки, в то время как в Gradient Boosting используется модель внутренней регрессии, итеративно обученная по остаткам. Это означает, что новые слабые ученики формируются с учетом входных данных, которые имеют высокие остатки.
В обоих алгоритмах параметр настройки лямбда или усадка еще больше замедляет процессы, позволяя большему количеству деревьев разной формы атаковать остатки.Это также известно как скорость обучения , поскольку она контролирует величину, с которой каждое дерево вносит вклад в модель. Как видите, Boosting также не включает в себя загрузку , вместо этого каждое дерево помещается в измененную версию исходных данных. Вместо подбора единого большого дерева решений, что приводит к жесткому подгонке данных и, возможно, к переобучению. Подход повышения учится медленно.
Как видите, алгоритм четко объясняется с помощью деревьев решений, но есть и другие причины, по которым он в основном используется с деревьями.
- Деревья решений являются нелинейными. Увеличение с помощью линейных моделей просто не работает хорошо.
- Слабый ученик должен быть неизменно лучше случайных догадок. Обычно вам не нужно настраивать параметры для дерева решений, чтобы получить такое поведение. Например, для обучения SVM действительно необходим поиск параметров. Поскольку данные повторно взвешиваются на каждой итерации, вам, вероятно, потребуется выполнить поиск другого параметра на каждой итерации.Таким образом, вы увеличиваете объем работы, которую вы должны сделать с большим отрывом.
- Деревья решений достаточно быстро обучаются. Так как мы собираемся построить 100 или 1000 из них, это хорошая собственность. Их также можно быстро классифицировать, что опять-таки важно, когда вам нужно запустить 100 или 1000, прежде чем вы сможете вывести свое решение.
- Изменяя глубину , вы получаете простой и легкий контроль над компромиссом смещения / дисперсии, , зная, что повышение может уменьшить смещение, но также значительно уменьшает дисперсию.
Это чрезвычайно упрощенное (возможно, наивное) объяснение повышения, но оно поможет вам понять самые основы. Популярная библиотека для реализации этого алгоритма – Scikit-Learn . Он имеет прекрасный API, который может запустить вашу модель с всего несколькими строками кода в Python .
Точность станка поднимется на новый уровень
Доктор Эндрю ЛонгстаффДоктор Эндрю Лонгстафф из Университета Хаддерсфилда проводит исследование, целью которого является значительное улучшение точности станков. Теперь он заработал возможность работать на одном из самых передовых в мире предприятий, и это могло обеспечить быстрый путь, который обеспечит более быстрое внедрение его разработок крупными производителями.
Доктор Лонгстафф – ведущий научный сотрудник Центра инновационного производства в области современной метрологии Университета EPSRC. Теперь он получил стипендию для работы с высокопроизводительной производственной катапультой (HVMC), которая частично финансируется Innovate UK. Схема финансируется Исследовательским советом по инженерным и физическим наукам и призвана помочь ученым работать с отраслевыми центрами, чтобы превратить свои исследования в коммерческую реальность.Катапульты описаны как «катализатор будущего роста и успеха производства в Великобритании».
Его стипендию HMVC увидит доктор Лонгстафф, работающий в Исследовательском центре передовых производств Университета Шеффилда с компанией Boeing (AMRC). Расположенный рядом с Ротерхэмом, AMRC является центром совместных исследований мирового уровня, который исследует и решает сложные производственные проблемы от имени своего большого реестра промышленных партнеров, в который входят такие глобальные аэрокосмические гиганты, как Rolls-Royce и BAE Systems, а также амбициозные региональные компании.
В течение следующих четырех лет, согласно условиям его стипендии, доктор Лонгстафф проведет в AMRC эквивалент шести месяцев. Он возьмет с собой новые передовые стратегии, разработанные им для количественной оценки точности станков и повышения предсказуемости изготавливаемых компонентов.
Он проведет испытания в AMRC, и его методы могут быть переданы компаниям, которые являются членами Центра.
«Речь идет о том, чтобы взять что-то, что было разработано в исследовательской среде, а затем распространять его более широко», – сказал доктор Лонгстафф.В результате повышенные уровни точности станков будут распространяться по всей производственной цепочке поставок, добавил он. Это может привести к резкому изменению стоимости и производительности производства в Великобритании.
В дополнение к элементу передачи знаний в Катапульте, есть еще один важный аспект исследований.
«Мы будем получать контролируемые производственные данные и коррелировать точность станка с окончательным выходом заготовки», – сказал доктор Лонгстафф. «Если вы пытаетесь сделать это непосредственно в отрасли, вы иногда изо всех сил пытаетесь получить контролируемые данные, чтобы установить эту корреляцию, но в более контролируемой среде AMRC у нас больше шансов убедиться, что мы сможем установить эту причину и следствие».”
3-D печать идет высокая скорость и большой объем
Предоставлено Университет Хаддерсфилда
Цитирование : Точность станков поднимется на новый уровень (25 июня 2015 г.) извлечено 20 июля 2020 г. с https: // физ.орг / Новости / 2015-06-станкостроительный-accuracy.html
Этот документ защищен авторским правом. Кроме честных сделок с целью частного изучения или исследования, нет Часть может быть воспроизведена без письменного разрешения. Содержание предоставлено исключительно в информационных целях.
, метрик для оценки вашего алгоритма машинного обучения | Aditya MishraОценка вашего алгоритма машинного обучения является неотъемлемой частью любого проекта. Ваша модель может дать вам удовлетворительные результаты при оценке с использованием метрики , скажем, precision_score , но может дать плохие результаты при сравнении с другими метриками, такими как logarithmic_loss или любой другой такой метрикой. В большинстве случаев мы используем точность классификации для измерения производительности нашей модели, однако этого недостаточно, чтобы действительно оценить нашу модель.В этом посте мы рассмотрим различные типы доступных показателей оценки.
Точность классификации
Логарифмическая потеря
Матрица путаницы
Область под кривой
Оценка F1
Средняя абсолютная ошибка
Средняя квадратическая ошибка
Классификационная точность – это то, что мы обычно имеем в виду, когда используем термин точность. Это отношение количества правильных прогнозов к общему количеству входных выборок.
Работает хорошо, только если есть равное количество образцов, принадлежащих каждому классу.
Например, предположим, что в нашем тренировочном наборе 98% выборок класса A и 2% выборок класса B. Тогда наша модель может легко получить 98% точности обучения , просто прогнозируя каждую тренировочную выборку, относящуюся к классу A.
Когда эта же модель тестируется на тестовом наборе с 60% выборками класса A и 40% выборками класса B, тогда точность теста снизится до 60%. Точность классификации велика, но дает нам ложное чувство достижения высокой точности.
Настоящая проблема возникает, когда стоимость неправильной классификации выборок младших классов очень высока. Если мы имеем дело с редким, но смертельным заболеванием, стоимость не диагностирования заболевания больного значительно выше, чем стоимость отправки здорового человека на дополнительные анализы.
Logarithmic Loss или Log Loss, работает, штрафуя ложные классификации. Это хорошо работает для мультиклассовой классификации. При работе с Log Loss классификатор должен назначать вероятность каждому классу для всех выборок.Предположим, что имеется N выборок, принадлежащих к M классам, тогда Log Loss вычисляется следующим образом:
, где,
y_ij, указывает, принадлежит ли выборка i к классу j или нет,
p_ij, указывает вероятность того, что выборка i принадлежит класс j
Log Loss не имеет верхней границы и существует в диапазоне [0, ∞). Log Loss ближе к 0 указывает на более высокую точность, тогда как если Log Loss от 0, то это указывает на более низкую точность.
Как правило, минимизация потерь в журнале дает большую точность классификатору.
Путаница Матрица, как следует из названия, дает нам матрицу в качестве вывода и описывает полную производительность модели.
Предположим, у нас есть проблема двоичной классификации. У нас есть несколько образцов, принадлежащих к двум классам: ДА или НЕТ. Также у нас есть собственный классификатор, который предсказывает класс для данной входной выборки. При тестировании нашей модели на 165 образцах мы получаем следующий результат.
Confusion MatrixСуществует 4 важных термина:
- Истинные положительные значения : случаи, в которых мы прогнозировали ДА, а фактический результат также составлял ДА.
- True Negatives : Случаи, в которых мы прогнозировали NO и фактический результат, были NO.
- Ложные срабатывания : Случаи, в которых мы прогнозировали ДА, а фактический результат был НЕТ.
- False Negatives : Случаи, в которых мы прогнозировали НЕТ и фактический результат, были ДА.
Точность для матрицы можно рассчитать, взяв среднее значение, лежащее на «главной диагонали» , т.е.
Область под кривой (AUC) является одним из наиболее широко используемых показателей для оценки. Используется для задачи бинарной классификации. AUC классификатора равна вероятности того, что классификатор будет ранжировать случайно выбранный положительный пример выше, чем случайно выбранный отрицательный пример. Прежде чем определить AUC , давайте разберемся с двумя основными терминами:
- Истинный положительный коэффициент (чувствительность) : Истинный положительный коэффициент определен как TP / (FN + TP) .Истинный положительный коэффициент соответствует доле точек положительных данных, которые правильно считаются положительными, по отношению ко всем точкам положительных данных.
- Истинный отрицательный коэффициент (специфичность) : Истинный отрицательный коэффициент определяется как TN / (FP + TN) . Коэффициент ложных положительных результатов соответствует доле точек отрицательных данных, которые правильно считаются отрицательными, по отношению ко всем точкам отрицательных данных.
- Неверно положительная ставка : Неверно положительная ставка определяется как FP / (FP + TN) .Коэффициент ложных положительных результатов соответствует доле отрицательных точек данных, которые ошибочно считаются положительными, по отношению ко всем отрицательным точкам данных.
Неверно положительный коэффициент и Истинный положительный коэффициент оба имеют значения в диапазоне [0, 1] . FPR и TPR рассчитываются при различных пороговых значениях, таких как (0,00, 0,02, 0,04,…, 1,00), и строится график. AUC – это область под кривой графика Неверная положительная ставка против истинной положительной ставки в разных точках [0, 1] .
Как видно, AUC имеет диапазон [0, 1]. Чем больше значение, тем выше производительность нашей модели.
F1 балл используется для измерения точности теста
F1 балл – это гармоническое среднее между точностью и отзывом. Диапазон для F1 балла составляет [0, 1]. Он говорит вам, насколько точен ваш классификатор (сколько экземпляров он классифицирует правильно), а также насколько он надежен (он не пропускает значительное количество экземпляров).
Высокая точность, но более низкий отзыв, дает вам чрезвычайно точную, но затем пропускает большое количество случаев, которые трудно классифицировать.Чем больше балл F1, тем лучше производительность нашей модели. Математически это можно выразить следующим образом:
F1 ScoreF1 Score пытается найти баланс между точностью и отзывом.
- Точность: Это число правильных положительных результатов, деленное на количество положительных результатов, предсказанных классификатором.
- Напомним: Это число правильных положительных результатов, деленное на число всех соответствующих образцов (все образцы, которые должны были быть определены как положительные).
Средняя абсолютная ошибка – это среднее значение разницы между исходными и прогнозируемыми значениями. Это дает нам меру того, как далеко были прогнозы от фактического результата. Тем не менее, они не дают нам никакого представления о направлении ошибки, т. Е. Не прогнозируем ли мы данные или не предсказываем ли мы данные. Математически это представляется следующим образом:
Среднее квадратичное отклонение (MSE) очень похоже на Среднее абсолютное отклонение, единственное отличие состоит в том, что MSE принимает среднее значение квадрата разности между исходными значениями и прогнозируемыми значениями.Преимущество MSE состоит в том, что легче вычислить градиент, в то время как средняя абсолютная ошибка требует сложных инструментов линейного программирования для вычисления градиента. Поскольку мы принимаем квадрат ошибки, эффект от более крупных ошибок становится более выраженным, чем от более мелких ошибок, поэтому модель теперь может больше фокусироваться на более крупных ошибках.
средняя квадратическая ошибкаВот и все.
Спасибо за чтение. Для любого предложения или запросов, оставьте свои комментарии ниже.
Как отмечали многие, было несколько ошибок в некоторых терминологиях.Думаю, мне следовало дважды прочитать статью, прежде чем публиковать ее. Ура!
Если вам понравилась статья, нажмите значок 👏, чтобы поддержать ее. Это поможет другим пользователям Medium найти его. Поделитесь этим, чтобы другие могли его прочитать.
| Технические характеристики токарно-винторезного станка 1В625МП/1500 | |
|---|---|
| Характеристики | Значение |
| Расстояние между центрами, мм. | 1500 |
| Максимальный диаметр обработки над станиной, мм. | 500 |
| Максимальный диаметр обработки над суппортом, мм. | 290 |
| Максимальный диаметр обработки в выемке станины, мм. | 690 |
| Диаметр циллиндрического отверстия в шпинделе, мм. | 70 |
| Конец шпинделя | 6 (ГОСТ 12593-93) |
| Центр в шпинделе | 7032-0054 (Метр.80) |
| Количество частот вращения (скоростей) шпинделя | 24 |
| Диапазон частот вращения шпинделя, об./мин. | 10 – 2000 |
| Диапазон продольной подачи, мм./об. | 0,032 – 28,0 |
| Диапазон поперечной подачи, мм./об. | 0,016 – 14,0 |
| Шаг нарезаемой метрической резьбы (число ступеней), мм. | 0,5 – 280 |
| Шаг нарезаемой модульной резьбы (число ступеней), модуль | 0,5 – 280 |
| Шаг нарезаемой дюймовой резьбы (число ступеней), нит./1` | 77 – 0,125 |
| Шаг нарезаемой питчевой резьбы (число ступеней), питч | 77 – 0,125 |
| Класс точности | П |
| Мощность привода главного движения, кВт | 7,1/6 |
| Номинальное напряжение питания, В | 380 |
| Габаритные размеры, мм. | 3300х1370х1700 |
| Масса 1В625МП/1500 , кг. | 2800 |
Промышленные весы Серия PCE-IS (класс III) | |||||||
Промышленные весы состоят из шкалы величин и эталонной шкалы. Предлагаем вам три модели с поверкой (легальные для торговли) и три других без поверки (но откалиброванные).Обе весы соединены интерфейсным кабелем. Контрольные весы позволяют рассчитать единичный вес с высокой точностью, а количественные весы производят подсчет штук на основе индивидуального веса, определенного с помощью контрольных весов. Эти промышленные масштабы идеально подходят для проведения инвентаризаций. Вы сможете очень быстро определить количество штук. Если вам нужно напечатать количество штук, вы можете запросить дополнительный принтер или подключить промышленные весы к своему ПК (комплект программного обеспечения по желанию) и выполнить прямую передачу данных.Все модели могут иметь калибровку ISO, но только три модели могут быть проверены. | |||||||
| |||||||
Количественная шкала Эти весы обеспечивают высокоточный подсчет штук на основе веса отдельной штуки, определенного с помощью эталонных весов. | Базовая шкала Эти весы позволяют рассчитать единичный вес с высокой точностью.Контрольные весы подключаются к количественным весам с помощью интерфейсного кабеля RS-232 (входит в комплект поставки). | ||||||
| Технические характеристики | |||||||
Весы промышленные без поверки (калиброванные) | |||||||
| Промышленные весы | Количественная шкала | Базовая шкала | |||||
| Масса диапазон [кг] | Читаемость [г] | Проверка значение [г] | Вес диапазон [г] | Читаемость [г] | Проверка значение [г] | Минимум размер [г] | |
| PCE – IS 01 | 60 | 20 | – – – | 2000 | 0.01 | – – – | 0,01 |
| PCE – IS 02 | 150 | 50 | – – – | 2000 | 0,01 | – – – | 0,01 |
| PCE – IS 03 | 300 | 100 | – – – | 2000 | 0,01 | – – – | 0,01 |
Весы промышленные с поверкой | |||||||
| Промышленные весы | Количественная шкала | Базовая шкала | |||||
| Масса диапазон [кг] | Читаемость [г] | Проверка значение [г] | Вес диапазон [г] | Читаемость [г] | Проверка значение [г] | Минимум размер [г] | |
| PCE – IS 01M | 60 | 20 | 20 | 2000 | 0.01 | 0,1 | 0,01 |
| PCE – IS 02M | 150 | 50 | 50 | 2000 | 0,01 | 0,1 | 0,01 |
| PCE – IS 03M | 300 | 100 | 100 | 2000 | 0,01 | 0,1 | 0,01 |
Технические характеристики обеих шкал (с / без поверки) | |||||||
| Время реакции | 5 с | ||||||
| Калибровка | С внешними калибровочными грузами для весов без поверки (опция) | ||||||
| Показатель | Количественная шкала: LED 14 мм / Базовая шкала: LED 18 мм | ||||||
| Размер кастрюли | Количественная шкала: 400 x 400 мм (для PCE-IS 01 / 01M) Количественная шкала: 600 x 490 мм (для PCE-IS 02/03 / 02M / 03M) | ||||||
| Корпус | Количественная шкала: нержавеющая сталь / Контрольная шкала: литой под давлением алюминий | ||||||
| Размеры | Количественная шкала: 400 x 500 x 130 мм (для PCE-IS 01 / 01M) Количественная шкала: 600 x 600 x 130 мм (для PCE-IS 02/03 / 02M / 03M) Базовая шкала: 240 x 275 x 90 мм | ||||||
| Электропитание | 230 В / 50 Гц | ||||||
| Защита | Количественная шкала: IP 54 / Справочная шкала: IP 54 | ||||||
| Масса | Количественная шкала: 12 кг (для PCE-IS 01 / 01M) Количественная шкала: 24 кг (для PCE-IS 02/03 / 02M / 03M) Базовая шкала: прибл.4 кг | ||||||
| Примеры различных применений системы подсчета штук | |||||||
| |||||||
Настоящим заявлением о соответствии мы письменно заявляем, что после оценки промышленные весы серии PCE-IS обладают особыми свойствами, указанными в декларации. Многоязычная спецификация сделана в соответствии с указаниями различных норм системы подсчета штук. Декларацию можно увидеть, нажав на соседнее изображение или символ PDF с инструкцией по эксплуатации (подписанной). | |||||||
| В комплект поставки входят 1 промышленные весы PCE-IS, состоящие из количественной и эталонной шкал, 1 интерфейсный кабель для подключения обоих весов, 2 сетевых адаптера и руководство пользователя | |||||||
| Дополнительные компоненты | |||||||
– Юридическая информация о проверке торговли (EICH-PCE-IS) Процедура проверки включает в себя процесс лабораторной калибровки и сертификацию в соответствии с правилами (законными для торговли) законодательства / проверки в Германии (на основе почтового индекса клиента).Имя и адрес клиента включены. Их принимают во всем мире. | | ||||||
– Калибровка ISO (ISO-PCE-IS) Процедура калибровки включает процесс лабораторной калибровки и сертификацию ISO. Имя и адрес клиента включены. Эти сертификаты сопоставимы с сертификатами NIST и UKAS. Их принимают во всем мире. | |||||||
– Комплект программного обеспечения (PCE-SOFT-IS) В комплект входит программное обеспечение для передачи данных взвешивания на ПК или портативный компьютер и кабель RS-232.Переданные данные также могут быть отправлены в другое программное обеспечение, такое как Excel и т. Д. Стандартное программное обеспечение на английском языке (также доступны другие языки: французский, немецкий и т. Д.). | | ||||||
– Принтер (PCE-BP) Принтер используется для прямого вывода данных взвешивания. Поставляется с кабелем RS-232, USB-кабелем, сетевым адаптером и 1 рулоном бумаги. – Ширина бумаги: 112 мм | |||||||
– Адаптер RS-232-USB (RS232-USB) Если ваш ПК или портативный компьютер использует USB-интерфейс, вы можете использовать адаптер вместе со стандартным кабелем RS-232.Программное обеспечение (включая актуальные драйверы) включено. | |||||||
| Здесь вы найдете обзор всех весов, доступных в предложении PCE Instruments. | |||||||
Обращайтесь: | Контактное лицо: | ||||||
| Эта страница на немецком, на итальянском, на испанском, на хорватском, на французском, на венгерском, на турецком, на польском, на русском, на португальском, на португальском, на португальском | |||||||
Информация о весах класса 3 | Шкала классов
Handbook 44 от NIST разъясняет правила и нормы для индустрии взвешивания и разделяет весовые устройства на пять классов точности.В зависимости от количества и значения делений шкалы оборудование может относиться к классу I, II, III, III L или IIII, причем класс I имеет наивысшую точность. Все весы Legal-for-Trade относятся к одному из этих пяти классов.
В Таблице 7a Руководства 44 дано подробное описание каждого класса. Класс III гласит: «Все коммерческие весы, если не указано иное, весы для проверки зерна, розничные взвешивание драгоценных металлов и полудрагоценных камней, весы для животных, почтовые весы, бортовые системы взвешивания транспортных средств с грузоподъемностью менее или равной 30 000 фунтов, и весы, используемые для определения стоимости стирки.”
По сути, он говорит, что все, что не попадает в другие категории, попадет в эту весовую категорию при условии, что устройство соответствует критериям количества и размера делений. Класс III охватывает множество различных типов чешуек, что делает его универсальным. Весы для производства будут одним из видов применения Класса III. В то время как некоторые ювелирные весы относятся к Классу III, если разрешение подходит для применения, в то же время более точные ювелирные шкалы могут относиться к Классу II. Все зависит от количества подразделений и мощности.Прецизионные лабораторные устройства обычно относятся к Классу I.
На противоположном конце спектра находится класс III L, который охватывает бортовые системы с большей грузоподъемностью, автомобильные весы, весы для скота и железнодорожные весы. Класс IIII применяется строго к осевым весам и устройствам колесных погрузчиков для обеспечения веса на шоссе.
Начните работу со шкалой Центральной КаролиныВ компании Central Carolina Scale философией всегда было работать напрямую с клиентами, чтобы помочь им выбрать подходящее оборудование для взвешивания.Если у вас есть конкретные вопросы о классах шкалы, позвоните нам по телефону (919) 776-7737 или напишите нам по адресу [email protected].
Точность | Ускоренный курс машинного обучения
Расчетное время: 6 минутТочность – это один из показателей для оценки моделей классификации. Неофициально Точность – это доля прогнозов, которые наша модель сделала правильно. Формально, точность имеет следующее определение:
$$ \ text {Точность} = \ frac {\ text {Количество правильных прогнозов}} {\ text {Общее количество прогнозов}} $$
Для двоичной классификации точность также может быть рассчитана с точки зрения положительных и отрицательных значений. следующим образом:
$$ \ text {Точность} = \ frac {TP + TN} {TP + TN + FP + FN} $$
Где TP = истинные положительные, TN = истинно отрицательные, FP = ложные положительные, и FN = ложноотрицательные.
Попробуем вычислить точность для следующей модели, которая классифицировала 100 опухолей как злокачественные (положительный класс) или доброкачественный (отрицательный класс):
Истинно Положительный (TP):
| Ложноположительный (FP):
|
Ложноотрицательный (FN):
| Истинно отрицательный (TN):
|
$$ \ text {Точность} = \ frac {TP + TN} {TP + TN + FP + FN} = \ frac {1 + 90} {1 + 90 + 1 + 8} = 0.91 $$
Точность составляет 0,91, или 91% (91 правильный прогноз из 100 возможных). Примеры). Это означает, что наш классификатор опухолей отлично справляется со своей задачей. выявления злокачественных новообразований, верно?
На самом деле, давайте сделаем более подробный анализ плюсов и минусов, чтобы получить больше понимания производительности нашей модели.
Из 100 примеров опухолей 91 являются доброкачественными (90 TN и 1 FP) и 9 злокачественных (1 ТП и 8 ФН).
Из 91 доброкачественной опухоли модель правильно определяет 90 как доброкачественный.Это хорошо. Однако из 9 злокачественных опухолей у модель только правильно определяет 1 как злокачественный – a ужасный исход, так как 8 из 9 злокачественных новообразований остаются недиагностированными!
Хотя на первый взгляд точность 91% может показаться хорошей, еще одна модель классификатора опухолей, которая всегда предсказывает доброкачественные достигнет такой же точности (91/100 правильных прогнозов) на наших примерах. Другими словами, наша модель не лучше той, что имеет нулевую прогностическую способность различать злокачественные опухоли от доброкачественных опухолей.
Сама по себе точность не дает полной картины, когда вы работаете с несбалансированным по классам набором данных , как этот, где есть существенное несоответствие между количество положительных и отрицательных меток.
В следующем разделе мы рассмотрим два лучших показателя. для оценки проблем с несбалансированными классами: точность и отзыв.
Ключевые терминыНарушение точности классификации для несбалансированного распределения классов
Последнее обновление 22 января 2021 г.
Точность классификации – это показатель, который суммирует производительность модели классификации как количество правильных прогнозов, деленное на общее количество прогнозов.
Его легко вычислять и интуитивно понятно, что делает его наиболее распространенным показателем, используемым для оценки моделей классификаторов. Эта интуиция рушится, когда распределение примеров по классам сильно искажается.
Интуиция, разработанная практиками для сбалансированных наборов данных, например, 99 процентов, представляющих искусную модель, может быть неверной и опасно вводить в заблуждение в отношении задач прогнозного моделирования несбалансированной классификации.
В этом руководстве вы обнаружите сбой в точности классификации для несбалансированных проблем классификации.
После прохождения этого руководства вы будете знать:
- Точность и частота ошибок являются стандартными показателями де-факто для обобщения производительности моделей классификации.
- Точность классификации не соответствует задачам классификации с асимметричным распределением классов из-за интуиции, выработанной практиками в отношении наборов данных с равным распределением классов.
- Интуиция о недостаточной точности для искаженных распределений классов на рабочем примере.
Начните свой проект с моей новой книги «Несбалансированная классификация с Python», включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
- Обновлено в январе 2020 г. : обновлено с учетом изменений в scikit-learn v0.22 API.
Точность классификации не соответствует действительности при искаженном распределении классов
Фото Эскви-Андо кон Тонхо, некоторые права защищены.
Обзор руководства
Это руководство разделено на три части; их:
- Что такое точность классификации?
- Ошибка при несбалансированной классификации
- Пример точности несбалансированной классификации
Что такое точность классификации?
Классификационное прогнозирующее моделирование включает прогнозирование метки класса на основе примеров в проблемной области.
Наиболее распространенный показатель, используемый для оценки эффективности модели прогнозирования классификации, – это точность классификации.Как правило, точность прогнозирующей модели хорошая (точность выше 90%), поэтому также очень часто резюмируют производительность модели с точки зрения коэффициента ошибок модели.
Точность и коэффициент дополнительных ошибок являются наиболее часто используемыми показателями для оценки эффективности обучающих систем в задачах классификации.
– Обзор прогнозного моделирования при несбалансированном распределении, 2015 г.
Точность классификации включает сначала использование модели классификации, чтобы сделать прогноз для каждого примера в наборе тестовых данных.Затем прогнозы сравниваются с известными метками для этих примеров в тестовом наборе. Затем точность рассчитывается как доля примеров в наборе тестов, которые были предсказаны правильно, деленная на все прогнозы, сделанные для набора тестов.
- Точность = правильные прогнозы / общие прогнозы
И наоборот, коэффициент ошибок можно рассчитать как общее количество неверных прогнозов, сделанных на тестовом наборе, деленное на все прогнозы, сделанные на тестовом наборе.
- Частота ошибок = неверные прогнозы / общие прогнозы
Точность и частота ошибок дополняют друг друга, что означает, что мы всегда можем рассчитать одно по другому. Например:
- Точность = 1 – Частота ошибок
- Коэффициент ошибок = 1 – точность
Еще один полезный способ думать о точности – это матрица неточностей.
Матрица неточностей – это сводка прогнозов, сделанных классификационной моделью, организованная в таблицу по классам.Каждая строка таблицы указывает фактический класс, а каждый столбец представляет прогнозируемый класс. Значение в ячейке – это количество прогнозов, сделанных для класса, которые фактически относятся к данному классу. Ячейки на диагонали представляют собой правильные прогнозы, в которых прогнозируемый и ожидаемый классы совпадают.
Самый простой способ оценить эффективность классификаторов основан на анализе матрицы неточностей. […] Из такой матрицы можно извлечь ряд широко используемых показателей для измерения производительности обучающих систем, таких как частота ошибок […] и точность…
– Исследование поведения нескольких методов балансировки данных обучения машинному обучению, 2004 г.
Матрица неточностей дает больше информации не только о точности прогнозной модели, но также о том, какие классы прогнозируются правильно, какие – неправильно, и какие типы ошибок допускаются.
Простейшая матрица неточностей предназначена для двухклассовой задачи классификации с отрицательным (класс 0) и положительным (класс 1) классами.
В этом типе матрицы неточностей каждая ячейка в таблице имеет конкретное и хорошо понятное имя, резюмируемое следующим образом:
| Положительный прогноз | Отрицательный прогноз Положительный класс | Истинно положительный (TP) | Ложноотрицательный (FN) Отрицательный класс | Ложно-положительный результат (FP) | Истинно отрицательный (TN)
| Положительный прогноз | Отрицательное предсказание Положительный класс | Истинно положительный (TP) | Ложноотрицательный (FN) Отрицательный класс | Ложноположительный (FP) | Истинно отрицательный (TN) |
Точность классификации может быть вычислена из этой матрицы неточностей как сумма правильных ячеек в таблице (истинно положительные и истинные отрицательные), разделенная на все ячейки в таблице.
- Точность = (TP + TN) / (TP + FN + FP + TN)
Аналогичным образом, коэффициент ошибок также можно рассчитать из матрицы неточностей как сумму неверных ячеек таблицы (ложных срабатываний и ложных отрицаний), деленную на все ячейки таблицы.
- Частота ошибок = (FP + FN) / (TP + FN + FP + TN)
Теперь, когда мы знакомы с точностью классификации и коэффициентом дополнительных ошибок, давайте выясним, почему они могут быть плохой идеей для использования в задачах несбалансированной классификации.
Хотите начать работу с классификацией дисбаланса?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
Ошибка точности при несбалансированной классификации
Точность классификации – это наиболее часто используемый показатель для оценки моделей классификации.
Причина его широкого использования заключается в том, что его легко вычислить, легко интерпретировать и представляет собой единое число, которое суммирует возможности модели.
Таким образом, его естественно использовать в задачах несбалансированной классификации, когда распределение примеров в обучающем наборе данных по классам неодинаково.
Это наиболее частая ошибка новичков в несбалансированной классификации.
Когда распределение классов немного искажено, точность все еще может быть полезным показателем. Когда расхождение в распределении классов является серьезным, точность может стать ненадежным показателем производительности модели.
Причина такой ненадежности кроется в среднестатистическом практикующем специалисте по машинному обучению и интуиции относительно точности классификации.
Как правило, прогнозирующее моделирование классификации практикуется с небольшими наборами данных, где распределение классов равно или очень близко к равному. Поэтому у большинства практиков возникает интуиция, что большая оценка точности (или, наоборот, низкая оценка коэффициента ошибок) – это хорошо, а значения выше 90 процентов – это хорошо.
Достижение 90-процентной точности классификации или даже 99-процентной точности классификации может быть тривиальной задачей для несбалансированной проблемы классификации.
Это означает, что интуиция для точности классификации, разработанная на основе сбалансированного распределения классов, будет применяться и будет ошибочной, вводя практикующего в заблуждение, заставляя думать, что модель имеет хорошие или даже отличные характеристики, хотя на самом деле это не так.
Парадокс точности
Рассмотрим случай несбалансированного набора данных с дисбалансом класса 1: 100.
В этой задаче каждый пример класса меньшинства (класс 1) будет иметь соответствующие 100 примеров для класса большинства (класс 0).
В задачах этого типа класс большинства представляет « нормальный », а класс меньшинства представляет « ненормальный », такой как неисправность, диагностика или мошенничество. Хорошие результаты в классе меньшинства будут предпочтительнее хороших результатов в обоих классах.
Принимая во внимание предвзятость пользовательского предпочтения к примерам меньшинства (положительного) класса, точность не подходит, потому что влияние наименее представленных, но более важных примеров снижается по сравнению с влиянием класса большинства.
– Обзор прогнозного моделирования при несбалансированном распределении, 2015 г.
По этой проблеме модель, которая предсказывает класс большинства (класс 0) для всех примеров в наборе тестов, будет иметь точность классификации 99 процентов, что отражает распределение основных и второстепенных примеров, ожидаемых в наборе тестов в среднем.
Многие модели машинного обучения разработаны на основе предположения о сбалансированном распределении классов и часто изучают простые правила (явные или иные), такие как всегда предсказывать основной класс, заставляя их достигать точности 99 процентов, хотя на практике они работают не лучше, чем неквалифицированный классификатор большинства.
Новичок увидит, что производительность сложной модели достигнет 99 процентов на несбалансированном наборе данных этого типа, и поверит, что их работа сделана, хотя на самом деле они были введены в заблуждение.
Эта ситуация настолько распространена, что получила название «парадокс точности».
… в рамках несбалансированных наборов данных точность больше не является надлежащей мерой, поскольку она не позволяет различать количество правильно классифицированных примеров разных классов. Следовательно, это может привести к ошибочным выводам…
– Обзор ансамблей для решения проблемы классового дисбаланса: подходы, основанные на заполнении, повышении и гибридном подходе, 2011 г.
Строго говоря, точность сообщает правильный результат; только интуиция практикующего о высоких показателях точности является точкой отказа.Вместо того, чтобы исправлять ошибочные интуитивные представления, обычно используются альтернативные метрики, чтобы суммировать производительность модели для несбалансированных проблем классификации.
Теперь, когда мы знакомы с идеей о том, что классификация может вводить в заблуждение, давайте посмотрим на рабочий пример.
Пример точности несбалансированной классификации
Хотя объяснение того, почему точность – плохая идея для несбалансированной классификации, было дано, это все еще абстрактная идея.
Мы можем конкретизировать сбой в точности на рабочем примере и попытаться противостоять любым интуитивным предположениям о точности сбалансированных распределений классов, которые вы, возможно, разработали, или, что более вероятно, отговорить от использования точности для несбалансированных наборов данных.
Во-первых, мы можем определить синтетический набор данных с распределением классов 1: 100.
Функция scikit-learn make_blobs () всегда будет создавать синтетические наборы данных с равным распределением классов.
Тем не менее, мы можем использовать эту функцию для создания наборов данных синтетической классификации с произвольным распределением классов с помощью нескольких дополнительных строк кода. Распределение классов можно определить как словарь, где ключ – это значение класса (например, 0 или 1), а значение – это количество случайно сгенерированных примеров для включения в набор данных.
Приведенная ниже функция с именем get_dataset () примет распределение классов и вернет синтетический набор данных с этим распределением классов.
# создать набор данных с заданным распределением классов def get_dataset (пропорции): # определяем количество классов n_classes = len (пропорции) # определить количество примеров, которые нужно сгенерировать для каждого класса наибольший = макс ([v вместо k, v в пропорциях.items ()]) n_samples = наибольший * n_classes # создать набор данных X, y = make_blobs (n_samples = n_samples, center = n_classes, n_features = 2, random_state = 1, cluster_std = 3) # собрать примеры X_list, y_list = список (), список () для k, v в пропорциях.Предметы(): row_ix = где (y == k) [0] selected = row_ix [: v] X_list.append (X [выбрано,:]) y_list.append (y [выбрано]) вернуть vstack (X_list), hstack (y_list)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # создать набор данных с заданным распределением классов def get_dataset (пропорции): # определить количество классов n_classes = len (пропорции) # определить количество примеров для генерации для каждого класса наибольший = макс ([v для k, v в пропорциях.items ()]) n_samples = large * n_classes # создать набор данных X, y = make_blobs (n_samples = n_samples, center = n_classes, n_features = 2, random_state = 1, cluster_std = 3) # собрать примеры X_list, y_list = list (), list () для k, v в пропорциях.items (): row_ix = where (y == k) [0] selected = row_ix [: v] X_list.append (X [selected,:]) y_list.append (y [selected]) вернуть vstack (X_list), hstack (y_list) |
Функция может принимать любое количество классов, хотя мы будем использовать ее для простых задач двоичной классификации.
Затем мы можем взять код из предыдущего раздела для создания диаграммы рассеяния для созданного набора данных и поместить его во вспомогательную функцию. Ниже приведена функция plot_dataset () , которая построит график набора данных и покажет легенду, чтобы указать сопоставление цветов с метками классов.
# точечная диаграмма набора данных, разный цвет для каждого класса def plot_dataset (X, y): # создать точечную диаграмму для образцов из каждого класса n_classes = len (уникальный (y)) для class_value в диапазоне (n_classes): # получить индексы строк для образцов с этим классом row_ix = where (y == class_value) [0] # создать разброс этих образцов пиплот.разброс (X [row_ix, 0], X [row_ix, 1], label = str (class_value)) # показать легенду pyplot.legend () # показать сюжет pyplot.show ()
# диаграмма разброса набора данных, разный цвет для каждого класса def plot_dataset (X, y): # создание диаграммы разброса для выборок из каждого класса n_classes = len (unique (y)) для class_value в range (n_classes): # получить индексы строк для образцов с этим классом row_ix = where (y == class_value) [0] # создать разброс этих образцов pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (class_value)) # показать легенду pyplot.legend () # показать график pyplot.show () |
Наконец, мы можем протестировать эти новые функции.
Мы определим набор данных с соотношением 1: 100, с 1000 примеров для класса меньшинства и 10 000 примеров для класса большинства, и построим график результата.
Полный пример приведен ниже.
# определить несбалансированный набор данных с соотношением классов 1: 100 из numpy import unique из numpy import hstack из numpy import vstack из импорта numpy, где из matplotlib import pyplot из склеарна.наборы данных импортируют make_blobs # создать набор данных с заданным распределением классов def get_dataset (пропорции): # определяем количество классов n_classes = len (пропорции) # определить количество примеров, которые нужно сгенерировать для каждого класса наибольший = макс ([v вместо k, v в пропорциях.items ()]) n_samples = наибольший * n_classes # создать набор данных X, y = make_blobs (n_samples = n_samples, center = n_classes, n_features = 2, random_state = 1, cluster_std = 3) # собрать примеры X_list, y_list = список (), список () для k, v в пропорциях.Предметы(): row_ix = где (y == k) [0] selected = row_ix [: v] X_list.append (X [выбрано,:]) y_list.append (y [выбрано]) вернуть vstack (X_list), hstack (y_list) # точечная диаграмма набора данных, разный цвет для каждого класса def plot_dataset (X, y): # создать точечную диаграмму для образцов из каждого класса n_classes = len (уникальный (y)) для class_value в диапазоне (n_classes): # получить индексы строк для образцов с этим классом row_ix = where (y == class_value) [0] # создать разброс этих образцов пиплот.разброс (X [row_ix, 0], X [row_ix, 1], label = str (class_value)) # показать легенду pyplot.legend () # показать сюжет pyplot.show () # определить распределение классов 1: 100 пропорции = {0: 10000, 1: 1000} # создать набор данных X, y = get_dataset (пропорции) # суммируем распределение классов: major = (len (где (y == 0) [0]) / len (X)) * 100 minor = (len (где (y == 1) [0]) / len (X)) * 100 print (‘Класс 0:% .3f %%, Класс 1:% .3f %%’% (основной, второстепенный)) # построить набор данных plot_dataset (X, y)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | # определить несбалансированный набор данных с соотношением классов 1: 100 из numpy import unique из numpy import hstack из numpy import vstack из numpy import, где из matplotlib import pyplot from sklearn.datasets import make_blobs # создать набор данных с заданным распределением классов def get_dataset (пропорции): # определить количество классов n_classes = len (пропорции) # определить количество примеров для генерации для каждого класса наибольший = макс ([v вместо k, v в proportions.items ()]) n_samples = наибольший * n_classes # создать набор данных X, y = make_blobs (n_samples = n_samples, center = n_classes , n_features = 2, random_state = 1, cluster_std = 3) # собрать примеры X_list, y_list = list (), list () для k, v в пропорциях.items (): row_ix = where (y == k) [0] selected = row_ix [: v] X_list.append (X [selected,:]) y_list.append (y [selected] ) return vstack (X_list), hstack (y_list) # диаграмма разброса набора данных, разные цвета для каждого класса def plot_dataset (X, y): # создание диаграммы разброса для выборок из каждого класса n_classes = len (unique (y)) for class_value in range (n_classes): # получить индексы строк для образцов с этим классом row_ix = where (y == class_value) [0] # создать разброс из этих образцов pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (class_value)) # показать легенду pyplot.legend () # показать график pyplot.show () # определить распределение классов 1: 100 пропорции = {0: 10000, 1: 1000} # создать набор данных X, y = get_dataset (пропорции) # обобщить распределение классов: major = (len (где (y == 0) [0]) / len (X)) * 100 minor = (len (где (y == 1) [0]) / len (X)) * 100 print (‘Класс 0:%.3f %%, Class 1:% .3f %% ‘% (major, minor)) # набор данных графика plot_dataset (X, y) |
При выполнении примера сначала создается набор данных и распечатывается распределение классов.
Мы видим, что чуть более 99 процентов примеров в наборе данных относятся к классу большинства, а немногим менее 1 процента – к классу меньшинства.
Класс 0: 99,010%, Класс 1: 0,990%
Класс 0: 99.010%, класс 1: 0,990% |
График набора данных создан, и мы видим, что есть еще много примеров для каждого класса и полезная легенда, указывающая на отображение цветов графика на метки классов.
Точечная диаграмма набора данных двоичной классификации с распределением классов от 1 до 100
Затем мы можем подобрать наивную модель классификатора, которая всегда предсказывает класс большинства.
Мы можем добиться этого с помощью DummyClassifier из scikit-learn и использовать стратегию « most_frequent », которая всегда будет предсказывать метку класса, которая наиболее часто встречается в наборе обучающих данных.
… # определить модель model = DummyClassifier (strategy = ‘most_frequent’)
… # определить модель model = DummyClassifier (strategy = ‘most_frequent’) |
Затем мы можем оценить эту модель на обучающем наборе данных, используя повторную k-кратную перекрестную проверку. Важно использовать стратифицированную перекрестную проверку, чтобы гарантировать, что каждое разделение набора данных имеет то же распределение классов, что и обучающий набор данных.Этого можно добиться с помощью класса RepeatedStratifiedKFold.
Функция extract_model () ниже реализует это и возвращает список оценок для каждой оценки модели.
# оценить модель, используя повторную k-кратную перекрестную проверку def оценивать_модель (X, y, метрика): # определить модель model = DummyClassifier (стратегия = ‘most_frequent’) # оценить модель с повторяющимся стратифицированным k-кратным cv cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) оценки = cross_val_score (модель, X, y, оценка = метрика, cv = cv, n_jobs = -1) возврат баллов
# оценить модель с помощью многократной перекрестной проверки в k раз повторное стратифицированное k-кратное cv cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) scores = cross_val_score (model, X, y, scoring = metric, cv = cv, n_jobs = -1) возвратные баллы |
Затем мы можем оценить модель и вычислить среднее значение каждой оценки.
Мы ожидаем, что наивный классификатор достигнет точности классификации около 99 процентов, что мы знаем, потому что это распределение большинства классов в наборе обучающих данных.
… # оценить модель оценки = оценка_модель (X, y, ‘точность’) # отчетный балл print (‘Точность:% .3f %%’% (среднее (баллы) * 100))
… # оценка модели оценка = оценка_модели (X, y, ‘точность’) # оценка отчета печать (‘Точность:%.3f %% ‘% (среднее (баллы) * 100)) |
Если объединить все это вместе, ниже приведен полный пример оценки наивного классификатора на синтетическом наборе данных с распределением классов 1: 100.
# оценить классификатор большинства классов на несбалансированном наборе данных 1: 100 из среднего значения импорта из numpy import hstack из numpy import vstack из импорта numpy, где из sklearn.datasets импортировать make_blobs из склеарна.фиктивный импорт DummyClassifier из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold # создать набор данных с заданным распределением классов def get_dataset (пропорции): # определяем количество классов n_classes = len (пропорции) # определить количество примеров, которые нужно сгенерировать для каждого класса наибольший = макс ([v вместо k, v в пропорциях.items ()]) n_samples = наибольший * n_classes # создать набор данных X, y = make_blobs (n_samples = n_samples, center = n_classes, n_features = 2, random_state = 1, cluster_std = 3) # собрать примеры X_list, y_list = список (), список () для k, v в пропорциях.Предметы(): row_ix = где (y == k) [0] selected = row_ix [: v] X_list.append (X [выбрано,:]) y_list.append (y [выбрано]) вернуть vstack (X_list), hstack (y_list) # оценить модель, используя повторную k-кратную перекрестную проверку def оценивать_модель (X, y, метрика): # определить модель model = DummyClassifier (стратегия = ‘most_frequent’) # оценить модель с повторяющимся стратифицированным k-кратным cv cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) оценки = cross_val_score (модель, X, y, оценка = метрика, cv = cv, n_jobs = -1) вернуть баллы # определить распределение классов 1: 100 пропорции = {0: 10000, 1: 1000} # создать набор данных X, y = get_dataset (пропорции) # суммируем распределение классов: major = (len (где (y == 0) [0]) / len (X)) * 100 minor = (len (где (y == 1) [0]) / len (X)) * 100 print (‘Класс 0:%.3f %%, класс 1:% .3f %% ‘% (основной, второстепенный)) # оценить модель оценки = оценка_модель (X, y, ‘точность’) # отчетный балл print (‘Точность:% .3f %%’% (среднее (баллы) * 100))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | # оценить классификатор большинства классов на несбалансированном наборе данных 1: 100 из numpy import mean из numpy import hstack из numpy import vstack из numpy import, где из sklearn.наборы данных import make_blobs from sklearn.dummy import DummyClassifier from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold # создать набор данных с заданным распределением классов dat def # определить количество классов n_classes = len (пропорции) # определить количество примеров, которые нужно сгенерировать для каждого класса large = max ([v для k, v в пропорциях.items ()]) n_samples = large * n_classes # создать набор данных X, y = make_blobs (n_samples = n_samples, center = n_classes, n_features = 2, random_state = 1, cluster_std = 3) # собрать примеры X_list, y_list = list (), list () для k, v в пропорциях.items (): row_ix = where (y == k) [0] selected = row_ix [: v] X_list.append (X [selected,:]) y_list.append (y [selected]) return vstack (X_list), hstack (y_list) # оценить модель, используя повторяющееся k-кратное пересечение -validation def Assessment_model (X, y, metric): # define model model = DummyClassifier (strategy = ‘most_frequent’) # оценить модель с повторяющейся стратифицированной k-кратностью cv cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) баллов = cross_val_score (модель, X, y, оценка = метрика, cv = cv, n_jobs = -1) возврат результатов # определение распределения классов 1: 100 пропорции = {0: 10000, 1: 1000} # создание набора данных X, y = get_dataset (пропорции ) # суммируем распределение классов: major = (len (где (y == 0) [0]) / len (X)) * 100 minor = (len (где (y == 1) [0 ]) / len (X)) * 100 print (‘Класс 0:%.3f %%, Класс 1:% .3f %% ‘% (основной, второстепенный)) # оценка модели оценка = оценка_модели (X, y,’ точность ‘) # оценка отчета print (‘ Точность :% .3f %% ‘% (среднее (баллы) * 100)) |
При выполнении примера сначала снова отображается распределение классов обучающего набора данных.
Затем модель оценивается и отображается средняя точность. Мы видим, что, как и ожидалось, производительность наивного классификатора в точности соответствует распределению классов.
Обычно достижение 99-процентной точности классификации было бы поводом для празднования. Хотя, как мы видели, из-за несбалансированного распределения классов 99 процентов на самом деле являются самой низкой приемлемой точностью для этого набора данных и отправной точкой, с которой должны улучшаться более сложные модели.
Класс 0: 99,010%, Класс 1: 0,990% Точность: 99,010%
Класс 0: 99,010%, Класс 1: 0.990% Точность: 99,010% |
Дополнительная литература
Этот раздел предоставляет дополнительные ресурсы по теме, если вы хотите углубиться.
Учебники
Документы
Книги
API
Статьи
Сводка
В этом руководстве вы обнаружили нарушение точности классификации для несбалансированных проблем классификации.
В частности, вы узнали:
- Точность и частота ошибок являются стандартными показателями де-факто для обобщения производительности моделей классификации.
- Точность классификации не соответствует задачам классификации с асимметричным распределением классов из-за интуиции, выработанной практиками в отношении наборов данных с равным распределением классов.
- Интуиция о недостаточной точности для искаженных распределений классов на рабочем примере.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разберитесь с несбалансированной классификацией!
Разработка несбалансированных моделей обучения за считанные минуты
…с всего несколькими строками кода Python
Узнайте, как в моей новой электронной книге:
Несбалансированная классификация с Python
Он предоставляет руководств для самообучения и сквозных проектов на:
Показатели производительности , Методы недодискретизации , SMOTE , Смещение порога , Калибровка вероятности , Зависимый от затрат алгоритм
и многое другое …
Внесите несбалансированные методы классификации в свои проекты машинного обучения
Посмотрите, что внутриКалибровочная машина для наращивания силы 5000kn 0.05 Класс точности с эталонным датчиком нагрузки, класс 00
Машина для калибровки наращивающего усилия использует группу стандартных динамометров с более высокой точностью, чем калиброванные в качестве стандарта. Он соединен последовательно с откалиброванным динамометром.
Перед запуском машины для калибровки силы наращивания высокоточный стандартный датчик и поддерживающий инструмент масштабируются, а затем собираются в основной раме машины для эталонной силы, а калибровочное значение вводится в компьютер. как установленное значение.После начала работы серводвигатель начинает приводить в действие масляный насос для создания давления в цилиндре, поршень сервоцилиндра перемещается для подачи масла, стандартный датчик и откалиброванный датчик одновременно подвергаются нагрузке, а выходные сигналы датчика отправляются на компьютер. стандартным динамометром и откалиброванным динамометром соответственно, и компьютер вычисляет разницу между стандартным выходным сигналом датчика (значением нагрузки) и заданным значением, а ошибка откалиброванного датчика рассчитывается согласно стандартному алгоритму.
Функция
Калибровка динамометров, датчиков или аналогичных инструментов.
Характеристики
1. Машина установлена в тележке и на плите со стандартным датчиком 5000 кН для уменьшения высоты помещения, толкайте и тяните передвижную тележку для облегчения установки и обеспечения точности;
2. Нагрузка значения силы обеспечивается двумя наборами масляных насосов, серводвигатель приводит в движение шариковый винт для нагрузки на масляный цилиндр, а масляный насос с большим потоком обеспечивает скорость подъема поршня, что удобно для регулировки пространства. , а серводвигатель делает управление более точным;
4.Самостоятельная разработка программного обеспечения для измерения и контроля, полностью автоматический контроль загрузки и разгрузки, автоматический сбор данных с датчиков, обработка и печать;
5. Функция проверки ползучести с датчиком
Технические характеристики
| Модель | BFS506B |
| Пропускная способность | 5000 кН |
| Класс точности | 905 Класс точности 905± 0.05% |
| Диапазон измерения | 500 кН ~ 5000 кН |
| Разрешение | 0,02% |
| Повторяемость | ± 0,05% |
| Погрешность | ± 0,05% |
| Пространство для испытаний (длина × ширина × высота мм) | 300 × 300 × 800 |
| Время загрузки для каждой ступени | 4-30 с |
| Время удержания силы | 30 с |
| Каркас сиденья и уровень компрессионной платформы | 0.3 мм / м |
| Размеры (длина x ширина x высота мм) | 1800 × 1200 × 3200 |
| Вес (т) | Около 17 |
Система автоматически управляется Алгоритм ПИД-регулирования. Когда система не нагружена, для управления используется сигнал обратной связи датчика перемещения (замкнутый контур перемещения). Когда система находится под действием силы, сигнал обратной связи датчика силы управляется (замкнутый контур силы).
Полностью цифровая система управления сервоприводом (замкнутым контуром), состоящая из компьютера, эталонного датчика и EDC-i20, в соответствии со значением поверочного усилия, установленным откалиброванным датчиком, устройство приложения силы спроектировано так, чтобы состоять из двух частей: устройство быстрой загрузки и устройство точной загрузки. За счет управления большим смещением (гидравлическим давлением) прикладывается около 90% заданного значения силы, а точное управление значением силы достигается за счет управления микроперемещением (или микрогидравлическим
).Система быстрой загрузки использует режим передачи гидравлического сервоуправления для приложения нагрузки к системе измерения нагрузки, а система прецизионной загрузки принимает режим передачи микрогидравлического сервоуправления для приложения нагрузки к системе измерения нагрузки и автоматически управляет машиной для завершения циклической проверки погрузка и разгрузка на всех уровнях. Благодаря компьютерной обработке файлов данных, в соответствии с процедурой проверки, кривая процесса загрузки может отображаться в реальном времени (кривая силы-времени).
Нарастите вверх класс точности машины 5000кн 0,05 калибровки силы с изображениями класса 00 ячейки нагрузки справки |
Legal для торговых весов – весы, одобренные NTEP
Legal для торговых весов – весы, одобренные NTEPLegal-For-Trade – Щелкните здесь, чтобы увидеть все LFT предлагаемые модели
Прецизионные весы предлагает большой выбор весов Legal-for-Trade.Вы можете увидеть все предлагаемые нами торговые весы ЗДЕСЬ. Наши самые популярные весы “Legal-for-Trade” – это A&D EK-610j, A&D EK-6100j, A&D. EK1200i, EK6000i, EK12Ki, EW1500i, И FX120iN, A&D FX200iN, A&D FX-300iN, И FX1200iN, A&D FX2000iN, A&D FX-3000iN, A&D HR60, Mettler-Toledo JE60 GE2-GE2-GE2-GE1-JT-32, Mettler-Toledo, Mettler, JE60, Mettler, Mettler, JE60, Mettler, JE60 Весы для ИБП Mettler PS60, вычислительные весы CAS SW-1-20LB, CAS S2000-60 JR, портативные настольные весы CAS PB-300, механические шкалы Chatillon 0723TG, весы для борьбы HealthoMeter 753KL, весы для аптеки Scientech ZSP400NP, используемые на производственных рынках, медицинская марихуана , прачечные самообслуживания, ювелиры, табачные, кофейные или кондитерские. “Legal for Trade” весы обычно считаются теми весами, которые предназначены изготовителем для использования в «коммерческие» приложения , где товар продается на развес. В то время как определение коммерческих приложений может незначительно отличаться в зависимости от юрисдикции мер и весов, Руководство NIST 44 (параграф Общего кодекса) G-A.1.) И NIST Handbook 130 (Закон о единых весах и мерах, раздел 1.13.) Определите коммерческое весоизмерительное оборудование следующим образом:
“….. мер и весов и весовые и измерительные приборы, коммерчески используемые или используемые при установлении размер, количество, протяженность, площадь или измерение количества, вещей, производить или товары для распространения или потребления, купленные, предложенные, или представлены для продажи, найма или награды, или при вычислении любой базовой платы или оплата оказанных услуг по весу или мере ».
Балансы Legal-for-Trade обычно стоит намного дороже, чем «Незаконно для торговли», поскольку для получения сертификата соответствия требуется обширное тестирование.Юридическая оценка торговых весов проводится в отношении конструкции устройства, работы, факторов окружающей среды и требований к маркировке. Несколько тестов увеличения / уменьшения нагрузки и сдвига проводятся. Весы протестированы в диапазоне температур от 10 ° C до 30 ° C (от 50 ° F до 86 ° F) на соответствие требованиям NTEP. Нагрузка примерно в половину грузоподъемности прикладывается к весам не менее 100 000 раз.
Строгие испытания требования обычно достигаются только в высококачественных балансах, включающих использование высококачественных электронных компонентов и передовой инженерии.Предложения для прецизионных весов огромный выбор баланса “Legal for Trade”.
Многие спрашивают – а зачем Я покупаю весоизмерительный прибор, предназначенный для торговли, если я не собираюсь использовать весы в коммерческом приложении для взвешивания? По нашему мнению, покупая весы “Legal-for-Trade”, вы будете знать, что получаете качественные прецизионные весы, которые прошли независимое тестирование для подтверждения соответствия весов спецификациям производителя.Если есть сопоставимая модель, построенная другим производителем, почему бы им не попытаться получить статус «легально для торговли»? В чем причина того, что они обычно не соответствуют требованиям?
По этой причине мы также рекомендуем весы A&D & Mettler по сравнению с весами любого другого производителя из-за того, что они производят многочисленные весы “Legal-for-Trade”. Взгляните на некоторых других производителей весов, и если вы увидите, что они не предлагают никаких «законных для торговли» весов, обычно это происходит потому, что они не могут произвести баланс качества, который мог бы пройти строгие испытания.
Для получения сертификата соответствия статуса “Legal-for-Trade” основное внимание при тестировании уделяется проверке соответствия весов техническим характеристикам. Типичное тестирование включает:
Весы проверены по указанному Диапазон напряжения. Пример: от 100 до 130 В переменного тока и от 10,0 до 12 В постоянного тока.
Температура. то есть: влияние Факторные испытания проводились при 20 ° C, -10 ° C, 5 ° C, 40 ° C и 20 ° C.
Точность – Половинная нагрузка вместимость помещена на весы более 100 000 раз .
Государственные органы мер и весов приняли Руководство 44, поэтому, за исключением случаев, когда отдельное государство приняло более конкретную формулировку для определения термина «коммерческий», будет применяться это общее определение. Определение того, что шкала является “законной” для торговых весов »начинается с того, что производитель разрабатывает весы для использования в коммерческих приложениях. Весы, отвечающие всем требованиям Справочника NIST 44 и применимых государственных и местных требований к весам и мерам будет считаться подходящим для “легальных для торговли” или коммерческих приложений.
Национальный Программа оценки типа (NTEP) выполняет оценку взвешивания и измерения соответствие устройств NIST Handbook 44. Многие государства требуют NTEP Сертификат соответствия на любое устройство для установки в коммерческом заявление. (Вы можете просмотреть эти состояния, для которых требуются сертификаты NTEP. и государства, которые имеют добровольную регистрацию сервисных агентств и сервисных Лица (VRSA), загрузив этот PDF-файл файл. Тестирование NTEP не «присваивает юридический статус для торговли» для устройство, это просто указывает на то, что оцениваемое устройство соответствует требованиям со Справочником 44. Например, в состоянии, отличном от NTEP, устройство не может требуется сертификат соответствия NTEP для использования в коммерческом приложении; от него может просто потребоваться выполнение требований Справочника 44 и соблюдение любых Дополнительные требования к государственным мерам и весам. Окончательное утверждение устройства в конкретной установке принадлежит государственным, местным или федеральным властям. должностное лицо, отвечающее за взвешивание и измерение, которое определяет, соответствует ли устройство всем требованиям Руководства. 44 требования, включая требования к установке и пригодности.
Некоторые производители, разрабатывающие весы, не предназначенные для использования в коммерческих или коммерческих целях, могут маркировать свои весы. с фразой “Not Legal for Trade”, чтобы гарантировать, что весы не используются в коммерческом приложении. MyWeigh Scales отмечает свои карманные весы Palmscale 7 «Not Legal for Trade» на нижней стороне весов.
Классы точности весов, производитель назначает класс точности устройства в зависимости от его конструкции и предполагаемого применения.Справочник 44 включает спецификации и допуски для каждой точности. класс. Для того, чтобы быть одобренным для использования в качестве особой точности по шкале классов, устройство должно соответствовать спецификациям, допускам, условиям использования и прочим требования к классу точности. Обзор типичных приложения для различных классов точности:
Устройства класса I и II обычно используются в лабораторное и более точное взвешивание. (Класс I 100 000+ дивизий) (II класс 10 000 – 100 000 делений). Примером весов, сертифицированных для класса I, являются весы Mettler JS1603C / A – 320 000 делений. Примерами весов, сертифицированных для класса II, являются A&D FX-1200iN, Mettler JS6002 или Scientech ZSE250
.Устройства класса III являются коммерческими весами. не указаны в других классах точности, а также включают весы, такие как почтовые весы, весы животных и другие. (Класс III 1000–10 000 делений) Примеры утвержденных цифровых весов класса III включают AND EK610j, A&D EK6100j, A&D EK600i, CAS NC-1 500, Ohaus A71P30DNUS и Mettler JE602.
Класс IIIL включает весы, такие как транспортные средства, осевая нагрузка, скот, железнодорожный путь, кран, бункер (кроме зерна) и т. д.
Класс IIII включает весы на колесах и переносные весы нагрузки на ось для контроля веса на шоссе. (См. Весы Код в Справочнике 44 для получения дополнительной информации.)
Многие люди звонят нам, чтобы объяснить, что означают «d» и «e», поэтому вот ответ:
Значение «d» – это наименьшее деление, отображаемое на шкале.
Значение «е» – это деление поверочной шкалы. Он представляет заявленную точность шкалы, когда на дисплее шкалы добавлены дополнительные единицы, чтобы расширить разрешающая способность. Деление поверочной шкалы (e) может быть больше отображаемого деление шкалы (d) для некоторых устройств.
Итак, как инспектор мер и весов классифицирует читаемость устройства взвешивания, когда «d» и «e» не равны? Например, AND EK6100J и Mettler JL6001GE имеют максимальную взвешивающую способность 6100 г и 6200 грамм соответственно с шагом отображения 0.1 грамм деления. «D» (значение деления шкалы) составляет 0,1 грамма, а «e» (значение деления поверочной шкалы) составляет 1 грамм.
Простой ответ заключается в том, что юридически, «d» не может рассматриваться в коммерческой сделке . Если у вас есть весы с d = 0,1 г и e = 1 г, то по закону весы имеют вес в 1 грамм и будут соответственно проверены и оценены. Буква «d» должна отображаться на шкале в отличие от всех других цифр, она может быть заключена в квадратные скобки, может быть затенена серым цветом, это может быть более мелкий шрифт и т. Д.
Сейчас есть несколько штатов, которые сегодня могут принимать значение «d», но в конечном итоге штаты будут принимать только «e». В ноябре 2015 года мы говорили с Николасом Бречумом, менеджером программы по стандартам измерений в штате Колорадо, и Колорадо принимает «d» для диспансеров медицинской марихуаны. Министерство сельского хозяйства Колорадо требует, чтобы диспансер каннабиса, который намеревается продавать медицинскую марихуану в количестве менее 1 унции, имел весы NTEP класса I или класса II с делением 0.01 грамм или меньше. Таким образом, в Колорадо аптеки медицинской марихуаны соответствуют требованиям весов при покупке AND EK610J, Mettler JL602GE, Mettler-Toledo JS3002GA, Mettler Toledo JS6002GA, A&D Weighing FX1200iN, FX2000iN или FX3000iN, Ohaus AX2X1 / EX622N или AX4202N / E. Все для вышеупомянутых цифровых весов имеют «d» = 0,01 грамма и «e» = 0,1 грамма.
Такие штаты, как Калифорния и Орегон, принимают только “e” . Для розничных магазинов, которые продают менее 1 унции каннабиса, вам понадобится шкала NTEP класса I или класса II, имеющая значение деления «е», равное 0.01 грамм или меньше. Таким образом, если вы работаете в аптеке медицинской марихуаны в Калифорнии и Орегоне, устройство для взвешивания, отвечающее требованиям, будет любым из следующих И Взвешивание FX120iN, FX200iN, FX300iN, Ohaus AX223N / E, AX423N / E, AX423N или AX523N / E. Все для вышеупомянутых цифровых весов имеют «d» = 0,001 грамма и «e» = 0,01 грамма.
Орегон требует, чтобы все производители, упаковщики и розничные торговцы марихуаны имели промышленные масштабы с действующим Сертификатом соответствия Национальной программы оценки типов (NTEP CC).Для производителя весов недостаточно сказать, что они «законны для торговли», у них должен быть сертификат NTEP CofC. После установки весов оператор должен заполнить Отчет о размещении в сервисе и заполнить заявку на лицензию. После того, как эти два документа будут представлены в Министерство сельского хозяйства штата Орегон, весы можно будет использовать на законных основаниях. Не нужно ждать появления инспектора мер и весов; Первоначальная проверка обычно происходит в течение 30 дней с момента получения документов.
При выборе цифровых весов они также должны подходить для применения. Вы можете оценить соответствие вашей системе взвешивания двумя основными вопросами; Какой минимальный вес продукта можно взвесить на весах? Какой максимальный вес продукта можно взвесить на весах? Минимальный вес покажет вам максимально допустимый размер деления весов, максимальный вес определяет требуемую вместимость. Весы обычно должны показывать 20 делений для минимального веса, который будет продаваться поверх них.
Например:
1) Ваш клиент рассчитывает взвесить марихуану на прилавке в диапазоне от 1 грамма до 200 граммов.
1 грамм / 20 делений = 0,05 грамма / деление
Вместимость должна быть не менее 200 грамм.
Подходит любая шкала с размером деления не более 0,05 грамма. Если бы у вас были весы вместимостью 200 х 0,01 г, они бы легко удовлетворили потребности клиентов.
Существует функциональный предел размера деления весов, если деление слишком маленькое, а в магазине сквозняк, шум или сильная вибрация, весы никогда не успокоятся и будут признаны непригодными. в зависимости от операционной среды.Инспектор мер и весов рассмотрит требования в руководстве пользователя весов при оценке пригодности окружающей среды, если окажется, что весы не работают должным образом. Весы Legal для торговли должны давать стабильные и повторяемые измерения при нормальных условиях.
2) Ваш клиент ожидает взвесить марихуану на прилавке в диапазоне от 1 грамма до 30 граммов, но также хочет использовать весы для получения до 2 фунтов упаковок марихуаны от своего поставщика.
1 грамм / 20 делений = 0,05 грамма / деление
1 фунт = 453,59237 грамма
Вместимость должна составлять 2 фунта или 907,18 грамма
В этом случае магазину может потребоваться шкала 1000 грамм x 0,01 грамма для удовлетворения требований
3) Фермер отправляет марихуану в упаковках от 2 до 5 фунтов на предприятие по переработке марихуаны.
2 фунта / 20 делений = 0,01 фунта / деление
Грузоподъемность должна быть не менее 5 фунтов.
В этом случае обычные весы для продуктового магазина 30 фунтов x 0,01 фунта или настольные весы, такие как A&D HV-15KGL, или даже очень доступные CAS SW-1-20LB (предлагают грузоподъемность 20 фунтов с шагом 0.Интервалы в 01 фунт) подходят для взвешивания продукта. Обратите внимание, что если вы используете программное обеспечение для раздачи медицинской марихуаны, такое как BioTrackTHC, вам понадобятся весы с интерфейсом RS232 для передачи результатов взвешивания с весов на ваш компьютер. CAS SW-1-20LB не имеет коммуникационного порта, поэтому HV-15KGL будет более подходящим, поскольку HV-15KGL имеет последовательный порт. Какое бы программное обеспечение для диспансера медицинской марихуаны вы ни выбрали, вы всегда хотите проверить, для какого производителя весов предназначено это программное обеспечение, ПЕРЕД покупкой весов.На рынке существует множество программ для продажи семян медицинской марихуаны, таких как BioTrackTHC, MJ Freeway, Webjoint, Ample Organics ERP, Green Bits, PROTEUS420, IndicaOnline EMR, Agrisoft Seed to Sale и многие другие, а некоторые предлагают очень ограниченный выбор масштабов своего программного обеспечения. буду общаться с.
Если бы производитель хотел делать меньшие партии, было бы разумнее иметь 2 весы с разными диапазонами взвешивания, чем пытаться купить 1, который покрывает такой большой диапазон.
Наконец, всегда нужно смотреть на значение размера деления.Веса и меры не учитывают цены на товары, когда требуют размера подразделения, скорее они обеспечивают соблюдение требования, чтобы разделение составляло не более 5% от общей транзакции. Вы можете позаботиться об этом и, возможно, захотите купить более дорогие весы, чтобы получить лучшее разрешение / точность. Инспектор требует только, чтобы весы были стабильными в той среде, в которой они надеются использовать их.
Возможность выполнять калибровку весов сильно различается в Соединенных Штатах. В некоторых штатах владельцу весов разрешается откалибровать цифровые весы перед вводом весового устройства в эксплуатацию, в то время как в других штатах требуется, чтобы калибровку выполнял лицензированный специалист по весам из вашего конкретного штата.Мы всегда рекомендуем вам позвонить в офис инспектора по весу и мерам, чтобы узнать, можете ли вы выполнить калибровку самостоятельно. В Орегоне владельцу или оператору весов разрешается калибровать и опечатывать весы. Тем не менее, для выполнения этой задачи вам понадобится подходящий калибровочный груз. Я могу вам сказать, что инспекторы по измерениям пометили многочисленные весы для марихуаны за несоответствие требованиям допуска просто потому, что весы не имели первоначальной калибровки, когда они были распакованы и подключены.
Все весы должны быть выровнены (регулируйте регулирующие ножки до тех пор, пока выравнивающий пузырек не будет отцентрирован) и откалибровать перед использованием. Люди, кажется, очень уверены, что шкала будет считываться правильно без каких-либо дополнительных усилий, и в большинстве случаев это не работает. Ваши весы необходимо откалибровать на месте установки, где они используются. Каждое место в мире позиционируется по-разному относительно «магнитного севера», и поэтому ускорение свободного падения немного отличается.Добавьте к этому атмосферное давление и ускорение свободного падения в зависимости от высоты вашего местоположения над уровнем моря.
Выбор подходящей контрольной гири зависит как от размера, так и от разрешения. Если для калибровки весов на 0,01 г требуется контрольная гиря весом 1 кг, то вам потребуется контрольная гиря с точностью до 1/3 деления шкалы или 0,01 г / 3 = 0,0034 г = 3,4 мг. Стандарт ASTM Class 1 на 1 кг допускает 2,5 мг. Если вы калибруете шкалу 0,1 г, 0,1 г / 3 = 0.034 г = 34 мг. Стандарт ASTM Class 4 на 1 кг имеет допуск 20 мг. (Пожалуйста, ознакомьтесь с нашими допусками по метрическому весу ЗДЕСЬ)
Информация, представленная на этой странице, является лишь кратким изложением правовых норм для торговых весов и весов. В Интернете есть множество информации, касающейся этой информации более подробно. Отличный источник ценной информации можно найти на сайте National Управление мер и весов Института стандартов и технологий. Вы также можете выполнить поиск на веб-сайте NIST и загрузить сертификат. соответствия здесь.Мы также рекомендуем вам связаться с вашим государством, местным, или Федеральное должностное лицо мер и весов для получения более подробной информации.
Дополнительные источники включают весы Ассоциация производителей. Весы и меры Министерства сельского хозяйства штата Орегон имеют свои Раздаточный материал NTEP онлайн здесь, где вы можете узнать больше о связанных с языком весам и мерам. Департамент сельского хозяйства штата Вашингтон излагает свои требования к шкале регулирования рекреационной марихуаны ЗДЕСЬ.
В заключение, выбор правильного масштаба для вашего коммерческого применения может иногда лучше всего отвечают люди, управляющие весами и измерениями программа для вашего государства. Предлагаем ссылку которые указаны в качестве государственных директоров по техническому обслуживанию и ремонту с указанием их номера телефона и адреса электронной почты и веб-сайт здесь.
Специальное примечание: Многие из законных торговых балансов теперь помечены как «Не для прямых продаж», и мы получаем много звонков от заинтересованных клиентов, которые думают, что их весы не являются законными для торговли, если на балансе есть этикетка. дисплей с пометкой «Не для прямых продаж».Будьте уверены, весы и весы, представленные на рынке прецизионных весов в категории «Весы для торговли» на нашей домашней странице, являются законными для торговли.
Многие весы имеют маркировку «Не для прямых продаж», так как теперь вес и меры требуют, чтобы и оператор весов, и потребитель могли видеть дисплей, показывающий вес. Если весы имеют только один дисплей, весы не должны использоваться для прямой транзакции между оператором весов и потребителем.Для прямых транзакций с потребителем лицом к лицу вам необходимо приобрести дополнительный дополнительный дисплей, чтобы потребитель мог видеть вес на своем дисплее. Мы предлагаем некоторые весы, на которых вы можете приобрести дополнительный дополнительный дисплей, и если это ваша ситуация, мы рекомендуем вам позвонить нам до совершения покупки.
Ниже приводится электронное письмо, которое мы получили от Джима Труекса, администратора NTEP на Национальной конференции мер и весов.
От: Jim Truex
Отправлено: Пятница, 26 декабря 2008 г., 18:15
Кому: Точные весы
Копия: Don Onwiler
Тема: не для прямой продажи этикеток
Пожалуйста, не путайте терминологию ” не для прямой продажи »с« не для торговли », так как они не совпадают.В терминологии мер и весов прямая продажа – это продажа, в которой присутствуют и покупатель, и продавец. Справочник NIST 44 требует, чтобы покупатель имел возможность наблюдать за транзакцией, и информация о транзакции формирует разумную позицию в заявке на прямую продажу.
Уверяю вас, что весы одобрены NTEP, разрешены для торговли и разрешены для использования в торговле.
Джим Труекс
Администратор NTEP
Национальная конференция мер и весов
1135 M Street, Suite 110 / Lincoln, Nebraska 68508
P.402.434.4880 D. 740.919.4350 F. 402.434.4878
www.ncwm.net
Отказ от ответственности: эта веб-страница предназначена для общего введения, она ни в коем случае не является исчерпывающим объяснением всех правил и не должна использоваться как таковой. Инспекторы мер и весов в разных штатах, округах или городах могут применять или интерпретировать постановление по-разному. Также проконсультируйтесь с регулирующим органом, ответственным за устройства для взвешивания, где вы планируете использовать цифровые весы, поскольку W&M Inspector определит, можете ли вы использовать выбранные вами весы для своих коммерческих приложений для взвешивания.
Горячий Покупает | Аналитические весы | Детские весы | Калибровка Веса | Подсчет Весы | Коммерческий Напольные весы | Кран Весы | Промышленная платформа И настольные весы | Механический Балансы | Влажный баланс | Карманные весы | Портативный Балансы | Точность Балансы Toploader | Цена Вычислительные весы | ИСПОЛЬЗОВАЛ & Демо-балансы | Свяжитесь с нами | Возвращение Политика | Дом Есть вопросы? Вызов 978-521-7095 или напишите нам по электронной почте, и мы поможем вам с выбором. Авторские права
© 2017 Прецизионные весы,
Все права защищены. |
Пять факторов, которые могут повлиять на точность вашей системы взвешивания
Сводка
- В этой статье обсуждаются пять факторов, которые могут повлиять на точность системы взвешивания, и даются советы по выбору, установке и эксплуатации системы с учетом этих факторов.
Вы можете гарантировать, что ваша система взвешивания работает точно, выбрав компоненты, подходящие для вашего применения, и предприняв шаги по контролю факторов окружающей среды и других сил, действующих на систему. В этой статье обсуждаются пять факторов, которые могут повлиять на точность системы взвешивания, и даются советы по выбору, установке и эксплуатации системы с учетом этих факторов.
Взвешивание для измерения количества и расхода сухого материала имеет несколько преимуществ: В отличие от измерения объема, взвешивание позволяет измерять количество материала без поправочных коэффициентов для объемной плотности материала.Взвешивание не требует контакта с материалом, что делает его пригодным для измерения коррозионных материалов и работы в агрессивных средах. Это также широко распространенный способ количественной оценки продаваемых упакованных продуктов.
Система взвешивания может иметь любую из нескольких форм, но обычно включает в себя один или несколько датчиков веса, которые поддерживают (или подвешивают) емкость или платформу для взвешивания, распределительную коробку и контроллер веса. Когда нагрузка прилагается к весовому судну или платформе, часть нагрузки передается на каждый датчик веса.Каждая ячейка посылает электрический сигнал, пропорциональный нагрузке, которую она воспринимает, через кабель к распределительной коробке. Сигналы весоизмерительных датчиков суммируются в распределительной коробке и отправляются через один кабель большего размера на контроллер веса, который преобразует суммированный сигнал в показание веса. На точность показаний веса может влиять качество компонентов системы, а также установка и работа системы в вашей среде.
Чтобы помочь вам выбрать высококачественные компоненты системы взвешивания, воспользуйтесь опытом поставщиков оборудования для взвешивания.Важной частью этого процесса выбора является определение того, как будет установлена система и какие факторы могут повлиять на ее работу после того, как она будет запущена на вашей технологической линии. Подумайте, как эти пять факторов могут повлиять на точность взвешивания вашей системы:
Точность датчика веса.
Коэффициенты нагрузки.
Силы окружающей среды.
Помехи при передаче сигнала.
КИПиА.
1. Точность датчика веса
Выбор высококачественного датчика веса для вашей системы взвешивания – это первый шаг к достижению точности взвешивания. Датчик нагрузки (также называемый датчиком нагрузки или преобразователем ) представляет собой кусок обработанного металла, который изгибается под действием механической силы нагрузки и преобразует механическую силу в электрический сигнал.Изгиб не превышает эластичности металла и измеряется тензодатчиками, закрепленными в точках на ячейке. Пока нагрузка приложена к нужному месту на датчике нагрузки, тензодатчики выдают пропорциональный электрический сигнал.
Ключевые характеристики датчика веса, которые будут предоставлять точную информацию о весе:
Нелинейность: ± 0,018% от номинальной мощности датчика веса.
Гистерезис: ± 0.025 процентов от номинальной мощности датчика веса.
Неповторяемость: ± 0,01% от номинальной мощности тензодатчика.
Ползучесть: ± 0,01% от номинальной мощности датчика веса за 5 минут.
Влияние температуры на выход: ± 0,0008 процентов нагрузки на градус Фаренгейта.
Влияние температуры на ноль: ± 0,001 процента от номинальной выходной мощности весоизмерительного датчика на градус Фаренгейта.
Описание спецификаций. Хотя каждая спецификация не обязательно применима к установке вашей системы взвешивания, важно понимать каждую спецификацию, чтобы определить общую точность весоизмерительного датчика.
Нелинейность – это максимальное отклонение калибровочной кривой весоизмерительной ячейки от прямой линии, начиная с нулевой нагрузки и заканчивая максимальной номинальной мощностью ячейки. Нелинейность измеряет погрешность взвешивания ячейки во всем рабочем диапазоне.Наихудший случай нелинейности ± 0,018 процента наблюдается во всем диапазоне тензодатчика. Чем меньше изменение веса вашего весоизмерительного датчика, тем меньше ошибка, связанная с нелинейностью.
Гистерезис – это разница между двумя показаниями выходного сигнала весоизмерительного датчика для одной и той же приложенной нагрузки – одно показание получено путем увеличения нагрузки от нуля, а другое – за счет уменьшения нагрузки от максимальной номинальной емкости весоизмерительной ячейки. Как и в случае с нелинейностью, в худшем случае ± 0.Спецификация гистерезиса 025% наблюдается во всем диапазоне датчика веса, и ошибка, вызванная гистерезисом, уменьшается с небольшими изменениями веса. В таких приложениях, как дозирование, где обычно требуются точные измерения веса только во время наполнения, вы можете игнорировать ошибку, вызванную гистерезисом. Ошибка гистерезиса обычно попадает в другую область калибровочной кривой весоизмерительного датчика, чем ошибка нелинейности, как показано на рисунке 1. В результате характеристики для этих двух ошибок объединяются на некоторых весоизмерительных датчиках в алгебраическую сумму, называемую объединенной ошибкой . , ± 0.03 процента.
Неповторяемость – это максимальная разница между выходными показаниями весоизмерительного датчика для повторных нагрузок при идентичных условиях нагружения (то есть, либо увеличивает нагрузку от нуля, либо уменьшает нагрузку от максимальной номинальной мощности весоизмерительной ячейки) и условиями окружающей среды. Спецификация неповторяемости составляет ± 0,01% от полного диапазона датчика веса. Неповторяемость может повлиять на измерение веса в любом приложении для взвешивания.Вы можете определить спецификацию неповторяемости наихудшего случая, добавив ошибку неповторяемости к объединенной ошибке весоизмерительного датчика.
Ползучесть – это изменение выходной мощности датчика веса с течением времени, когда нагрузка остается на датчике в течение длительного времени. При 2–3-минутном цикле замеса или наполнения ползучесть не является серьезной проблемой. Но если вы используете тензодатчики для мониторинга запасов в хранилище, вам необходимо учитывать эффекты ползучести.
Изменения температуры могут вызвать ошибки при взвешивании.Большинство тензодатчиков имеют температурную компенсацию, чтобы уменьшить эти ошибки. Но если ваша система взвешивания подвержена значительным перепадам температуры во время цикла взвешивания – например, если емкость для взвешивания вне помещения подвергается воздействию низких ночных температур, но быстро нагревается на дневном солнце, – подумайте, как температура может повлиять на выходную мощность датчика веса. . Если единственное существенное изменение, влияющее на вашу систему взвешивания, – это разница между летними и зимними температурами, вы можете повторно откалибровать датчики веса один раз при смене сезона, чтобы исправить любые ошибки, вызванные температурой.
Изменения температуры влияют на выход датчика веса, изменяя чувствительность датчика веса, и вы должны учитывать этот эффект, если вы не выполняете новую калибровку для каждого большого изменения температуры. Температурное воздействие на тензодатчик при нулевой нагрузке приводит к смещению всего выходного диапазона датчика. Но если весоизмерительный датчик снова обнуляется (т. Е. Тарирует в режиме веса нетто) до того, как он начинает цикл взвешивания – например, в приложении для дозирования – вам не нужно беспокоиться об этом температурном влиянии на нулевую нагрузку.
Учитывая время отклика вашего весоизмерительного датчика. Время отклика тензодатчика – еще один фактор, который следует учитывать в некоторых приложениях. Типичный датчик веса ведет себя как жесткая пружина, которая колеблется, поэтому для получения точных показаний веса датчик нагрузки должен стабилизироваться, то есть прекратить колебания, за меньшее время, чем требуется период взвешивания. В то время как время отклика весоизмерительного датчика обычно не имеет значения для дозирования, высокоскоростная машина для контрольного взвешивания или роторная разливочная машина требует быстродействующих весоизмерительных датчиков.Такие весоизмерительные ячейки подавляют собственную частоту колебаний при приложении к ним нагрузки. Тем не менее, весоизмерительные ячейки не отражают вибрации, приложенные к ним от внешних источников, таких как близлежащее оборудование, поэтому вам все равно необходимо изолировать весоизмерительные ячейки от таких источников вибрации (более подробно это описано в следующем разделе «3: Воздействие окружающей среды. “).
2. Факторы нагрузкиУбедитесь, что нагрузка приложена к каждому датчику веса в вашей системе взвешивания, как указано производителем.Неправильно приложенная нагрузка, такая как скручивающая нагрузка, заставляет тензодатчики в ячейке испытывать напряжение и передавать изменение сигнала, пропорциональное скручиванию, а не весу груза.
Для точного взвешивания только тензодатчики должны выдерживать весь измеряемый вес. Например, жесткие кабельные соединения и жестко смонтированные трубопроводы на весовом судне будут поддерживать часть нагрузки и предотвращать передачу общей нагрузки на датчики веса. Чтобы избежать этой проблемы, используйте гибкие соединения, которые не выдерживают часть нагрузки.А если вы используете амортизаторы или контрольные стержни, чтобы весовое судно не раскачивалось и не раскачивалось, убедитесь, что они не выдерживают никакой нагрузки.
Правильно выровняйте каждую точку нагрузки в сборе, то есть каждый датчик нагрузки и его монтажное оборудование, чтобы гарантировать, что монтажное оборудование направляет нагрузку непосредственно через датчик нагрузки. Например, для датчиков веса с компрессионной установкой под бункером выровняйте каждый узел точки нагрузки непосредственно под опорой бункера, чтобы избежать вытягивания или толкания между узлами на других опорах.Каждый датчик веса должен быть выровнен, и все они должны быть в одной плоскости, чтобы гарантировать, что они равномерно распределяют нагрузку.
Убедитесь, что пол или конструкция под тензодатчиками достаточно прочны, чтобы выдерживать вес емкости и ее содержимого, а также вес другого оборудования, лежащего на том же полу или конструкции, без прогиба. Это гарантирует, что узлы точки нагрузки остаются на уровне ± 0,5 процента от нуля до полной нагрузки, и предотвратят нежелательные боковые нагрузки на датчики веса, которые могут ухудшить точность системы взвешивания.
Если ваше весовое судно имеет длинные веретенообразные ножки, ножки могут раздвигаться, когда материал загружается в емкость. Это создает боковые нагрузки для датчиков веса и может вызвать заедание системы, которое не позволяет датчикам веса воспринимать полную нагрузку. Вы можете добавить поперечные распорки к ногам, чтобы усилить конструкцию и сохранить точность взвешивания.
3. Экологические силыУбедитесь, что только сила веса передается на каждый датчик веса.Другие силы, включая силы окружающей среды, такие как ветровая нагрузка, ударная нагрузка, вибрация, большие изменения температуры и перепады давления, могут вызывать ошибки в сигнале датчика веса.
Ветровая нагрузка. Ветровая нагрузка может повлиять на систему взвешивания вне помещения или систему внутри помещения с низкой производительностью. Например, на открытом воздухе боковой ветер со скоростью 30 миль в час на весовом судне оказывает на тензодатчики силы, которые не имеют ничего общего с весом, в результате чего наветренные ячейки воспринимают меньшую нагрузку, а подветренные ячейки – более тяжелую нагрузку.В таком случае используйте датчики нагрузки большей емкости, чтобы предотвратить перегрузку ячеек с подветренной стороны. Внутри помещения активное воздушное отверстие для кондиционирования воздуха также может привести к неточным измерениям с небольшим шагом (например, 1 унция) в системе взвешивания малой емкости, такой как небольшие платформенные весы. Вы можете использовать покрытие из оргстекла поверх платформенных весов, чтобы заблокировать или отвести паразитные воздушные потоки.
Для точного взвешивания только тензодатчики должны выдерживать весь измеряемый вес.
Ударная нагрузка. Ударная нагрузка возникает, когда тяжелый материал сбрасывается на систему взвешивания, вызывая силы, превышающие номинальную грузоподъемность системы, и приводя к повреждению системы. Вы можете использовать весоизмерительные ячейки большей емкости, которые могут выдерживать эту ударную нагрузку, но это ухудшит разрешающую способность системы (наименьшее приращение, которое система может весить). Управление потоком материала в систему взвешивания с помощью питателя, специально разработанного загрузочного желоба или другого устройства может предотвратить повреждение при ударной нагрузке.
Вибрация. Вибрация от технологического оборудования и других источников рядом с системой взвешивания может заставить датчики веса измерять вес материала, а также передаваемую на них вибрацию, которую датчики воспринимают как механический шум. Вы можете уменьшить или предотвратить эффекты вибрации, изолировав систему взвешивания от источников вибрации, когда это возможно, или используя контрольно-измерительные приборы системы взвешивания с алгоритмами, устраняющими эффекты вибрации.
Большие перепады температуры. Вне зависимости от того, находится ли ваше весовое судно в помещении или на открытом воздухе, большие перепады температуры могут вызвать его расширение или сжатие. Это вызывает ошибки в считывании веса и может повредить датчики веса. Если ваша система взвешивания подвергается значительным перепадам температуры, установите датчики веса и монтажное оборудование, которое может выдержать расширение и сжатие емкости.
Перепад давления. Перепад давления может вызвать ошибки при взвешивании из-за приложения к системе взвешивания нежелательных сил.Перепад давления может возникать, например, когда емкость для взвешивания устанавливается между цехом с повышенным давлением и другим полом при атмосферном давлении. Чтобы свести к минимуму ошибки при взвешивании, откалибруйте весоизмерительные ячейки по постоянному уровню давления на полу с повышенным давлением. Если давление непостоянно, установите емкость для взвешивания в другом месте.
Перепад давления может вызвать ошибки при взвешивании из-за приложения нежелательных сил к системе взвешивания.
Другая форма перепада давления создается в невентилируемой емкости для взвешивания: когда материал быстро течет в закрытую емкость для взвешивания, он вытесняет объем воздуха, равный объему материала.Если воздух не может выйти из емкости через вентиляционное отверстие, гибкие соединения, которые соединяют впускной и выпускной трубопровод материала с емкостью для взвешивания, будут расширяться по мере того, как в нее проникает несмещенный воздух, и это расширение будет оказывать боковые силы на тензодатчики. , создавая ошибки взвешивания. Чтобы предотвратить эту проблему, правильно вентилируйте весовую емкость.
4. Помехи при передаче сигналаПомимо того, что весоизмерительные ячейки измеряют только желаемый вес, не менее важно, чтобы весовой контроллер измерял только электрический сигнал весоизмерительной ячейки.Радиочастотные помехи (RFI), электромеханические помехи (EMI), влажность и температура могут мешать этому электрическому сигналу.
RFI и EMI. Подобно тому, как вибрация – это механический шум (то есть помехи) для весоизмерительного датчика, RFI и EMI – это электрические помехи для сигнала весоизмерительного датчика, отправляемого от ячеек к контроллеру веса. Источники RFI и EMI включают молнии, портативные двусторонние радиостанции, большие линии электропередач, статическое электричество, соленоиды и электромеханические реле.Одним из основных шагов к тому, чтобы эти источники электрического шума не влияли на точность взвешивания, является изоляция низковольтного сигнала весоизмерительной ячейки (обычно равного 1 миллионной выходной мощности батареи фонарика) в экранированном кабеле, а затем прокладка кабеля в кабелепроводе отдельно от другие кабели. Но имейте в виду, что экран кабеля тензодатчика также может быть открытой дверью для электрических помех. Чтобы шум не влиял на работу весоизмерительного датчика, правильно заземлите экран, привязав его только на одном конце к истинному заземлению, что предотвратит образование петли заземления на экране.
Влажность. Влага, попадающая в распределительную коробку системы взвешивания, может проникать в кабели к каждому весоизмерительному датчику и уменьшать емкость между сигнальными линиями. Это приводит к тому, что линии возбуждения тензодатчиков (линии, передающие электрическую энергию к ячейкам) соединяются с сигнальными линиями (линиями, передающими сигналы ячеек обратно в распределительную коробку), создавая электрические помехи, которые могут повлиять на точность взвешивания. Чтобы избежать этого, используйте водонепроницаемую распределительную коробку NEMA 4 и заглушите все неиспользуемые отверстия распределительной коробки.Если в вашей среде присутствует влага, также используйте датчики веса, которые герметично закрыты как в области тензодатчика, так и в кабельном вводе. Зона тензодатчика должна быть приварена. Кабельный ввод, который наиболее уязвим для влаги, поскольку влага может просачиваться через кабель, должен иметь сварной фитинг с герметичным коллектором стекло-металл.
Температура. Кабельный канал для тензодатчиков, подверженный значительным перепадам температуры или проложенный более чем на 50 футов от распределительной коробки до весового контроллера, может подвергаться воздействию колебаний температуры, которые вызывают изменения сопротивления кабеля.Это может вызвать изменения возбуждения, что, в свою очередь, приведет к изменению сигнала датчика веса. Чтобы предотвратить эти проблемы с температурой, используйте шестипроводной кабель датчика веса, который позволяет контроллеру веса делать ратиометрические показания сигнала датчика веса, игнорируя изменения, вызванные изменением возбуждения.
5. КИПиАСледование советам, приведенным в предыдущих четырех разделах, гарантирует, что сигнал вашего датчика веса будет поступать на контроллер веса в максимально чистой форме.Но есть вероятность, что сигнал все равно не будет абсолютно чистым. Почему нет? Помните, что датчик нагрузки передает сигнал, представляющий механическую силу, а вибрация равна механической силе. Точно так же весовой контроллер измеряет электрический сигнал, а RFI и EMI – это электрических сигналов. Но даже если вы не можете полностью устранить источники механических и электрических шумов, вы можете выбрать контроллер веса, который поможет очистить неидеальные сигналы веса и повысить точность взвешивания.
Как весовой контроллер очищает весовые сигналы. Давайте посмотрим, как весовой контроллер может очистить весовой сигнал от тензодатчика. Рассмотрим пример сигнала, поступающего от типичного весового бункера, как показано на рисунке 2a. Теоретически весовой сигнал должен плавно перемещаться вверх на графике на Рисунке 2а по мере поступления материала в бункер. Но на самом деле сигнал может двигаться медленно из-за раскачивания и раскачивания бункера или материала, поступающего в бункер импульсами, например, из неправильно установленного шнека.Механическая вибрация, например, от мешалки с бункером или близлежащего технологического оборудования, или электрические помехи, например, от расположенных поблизости крупных линий электропередач, также могут вызвать быстрое дрожание сигнала.
Если сигнал поступает на весовой контроллер, оснащенный аналоговым фильтром нижних частот (обычно номиналом от 5 до 20 герц), фильтр устраняет случайное дрожание, тем самым обеспечивая аналоговое усреднение, и выдает сигнал, аналогичный показанному на рисунке. 2b.
Весовой контроллер, оснащенный аналого-цифровым преобразователем с двойным наклоном, также может помочь в цифровом усреднении других случайных колебаний сигнала.Как только контроллер оцифровывает сигнал, он может усреднить показания, чтобы сгладить медленное вращение и выдать репрезентативный сигнал, подобный показанному на рисунке 2c. Такое цифровое усреднение особенно полезно для усреднения от 1 до 250 показаний за цикл взвешивания, когда система взвешивания настроена на получение показаний веса с шагом в одну единицу (например, с шагом в 1 фунт, а не с шагом 5 фунтов в системе. с диапазоном 200 фунтов). В некоторых приложениях вам, возможно, придется использовать весовой контроллер, который также предоставляет встроенные собственные алгоритмы, которые автоматически устраняют влияние колебаний сигнала до нуля.25 герц.
Требования к контроллеру веса. Контроллеру веса требуется несколько других функций для обеспечения точности веса. Контроллер должен иметь аналого-цифровой преобразователь, который может быть синхронизирован с частотой сети 60 герц, чтобы избежать проблемы “гула 60 герц”, вызванного шумом от линий электропередачи и оборудования 60 герц. Внутренние компоненты контроллера должны обеспечивать надлежащее экранирование аналогового сигнала, чтобы изолировать сигнал от паразитных помех.Аналоговая схема контроллера также должна иметь высококачественные электрические компоненты для точной обработки низковольтных весовых сигналов весоизмерительных ячеек.
Наконец, рассмотрите три основных спецификации контроллера веса, чтобы гарантировать точность вашей системы взвешивания:
Нелинейность: ± 0,01 процента диапазона (т. Е. Выбранного рабочего диапазона системы взвешивания).
Влияние температуры на ноль: ± 0.0027 процентов диапазона на градус Фаренгейта.
Влияние температуры на выходной сигнал: ± 0,0027 процента шкалы на градус Фаренгейта.
Как и в случае с датчиком веса, влияние нелинейности на весовой контроллер незначительно при небольших изменениях веса. Вы также можете игнорировать влияние температуры на ноль, если контроллер тарирует перед запуском цикла взвешивания. Однако вам необходимо учитывать, как влияние температуры на производительность может повлиять на точность взвешивания.
Какую точность вы можете ожидатьДавайте вычислим наихудшую общую ошибку взвешивания для примера системы взвешивания, чтобы увидеть, как компоненты системы влияют на точность. Мы рассмотрим общую ошибку наихудшего случая только для датчиков веса и контроллера веса в системе дозирования с увеличением веса.
Эта система весит 400 фунтов материала в бункере на 100 фунтов, при этом весоизмерительные ячейки должны выдерживать в сумме не менее 500 фунтов.Бункер подвешен на трех тензодатчиках, каждый с номинальной вместимостью 200 фунтов, что дает общую вместимость 600 фунтов. Между сезонными калибровками системы также происходит изменение температуры на 20 ° F.
В процессе дозирования нас интересуют только спецификации компонентов системы взвешивания на нелинейность, неповторяемость и влияние температуры на выход, а ошибка нелинейности не вызывает беспокойства, поскольку дозирование представляет собой последовательность частичных взвешиваний.
В результате формула для вычисления общей ошибки системы в наихудшем случае будет:
[(IT) 2 + (LN) 2 + (LT) 2 ] 1/2
, где IT – влияние температуры прибора (весового контроллера) на выход (0.000027 x 600 фунтов x 20 ° F), LN – неповторяемость тензодатчика (0,0001 x 600 фунтов), а LT – влияние температуры датчика веса на выход (0,000008 x 500 фунтов x 20 ° F). В этом примере общая ошибка наихудшего случая составляет 0,34 фунта. Помните, что это наихудшее число; правильно установленная система взвешивания дает меньшую погрешность.
Последнее предупреждениеДостижение такой точности взвешивания означает учет многих факторов, как механических, так и эксплуатационных, которые могут повлиять на вашу систему взвешивания.Выбор качественных компонентов, особенно подходящих для вашего приложения, будет иметь большое значение для обеспечения необходимой точности вашей системы. Эти компоненты обычно имеют впечатляющие характеристики для наихудшего случая, а их фактическая производительность обычно лучше, чем в спецификации. Как правило, выбирайте датчики веса и контроллер веса с точностью в 10 раз лучше, чем точность вашей системы. И обратите особое внимание на то, как вы устанавливаете и эксплуатируете систему, чтобы механические силы и электрический шум не снижали точность вашего взвешивания.
Эта статья предоставлена Hardy Instruments. Тед Копчински – менеджер по маркетингу продукции в Hardy Instruments, 3860 Calle Fortunada, San Diego, CA -1825; 858-278-2900, доб. 1210, факс 858-278-6700. Он имеет степень бакалавра электротехники в Государственном университете Сан-Диего и степень магистра делового администрирования в Национальном университете Сан-Диего. Дэйв Несс – президент и генеральный директор компании, имеет степень бакалавра электротехники в Государственном университете Сан-Диего и степень магистра делового администрирования в Национальном университете.
Об авторе
Тед Копчински – менеджер по маркетингу продукции в Hardy Instruments, 3860 Calle Fortunada, San Diego, CA -1825; 858-278-2900, доб. 1210, факс 858-278-6700. Он имеет степень бакалавра электротехники в Государственном университете Сан-Диего и степень магистра делового администрирования в Национальном университете Сан-Диего. Дэйв Несс – президент и генеральный директор компании, имеет степень бакалавра электротехники в Государственном университете Сан-Диего и степень магистра делового администрирования в Национальном университете.
Для получения дополнительной информации нажмите здесьВам понравилась эта замечательная статья?
Ознакомьтесь с нашими бесплатными электронными информационными бюллетенями, чтобы прочитать больше замечательных статей .