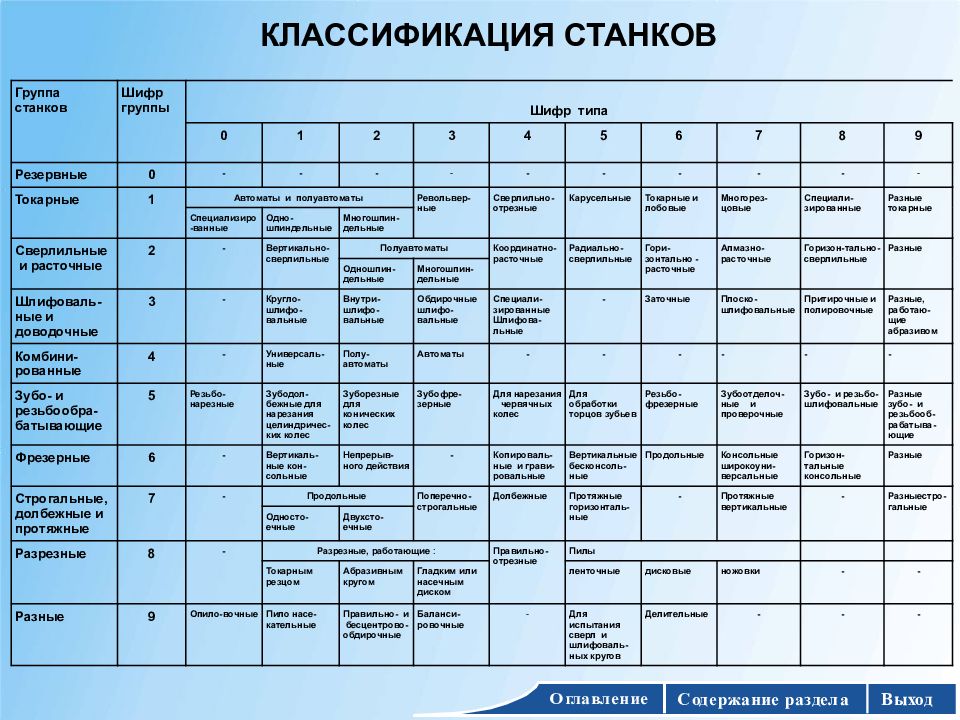
1. Классификация металлорежущих станков по технологическим признакам. Обозначение моделей
Металлорежущий станок – машина для размерной обработки заготовок, в основном, путем снятия стружки. Помимо основной рабочей операции, связанной с изменением формы и размеров заготовки, на станке необходимо осуществлять вспомогательные операции для смены заготовок, их зажима, измерения, операции по смене режущего инструмента и т.п.
Классификация по технологическим признакам
В основу классификации станков по технологическим признакам положены такие признаки, как:
В зависимости от
целевого назначения для обработки тех
или иных деталей или поверхностей,
выполнения технологических операций
и режущего инструмента станки
подразделяются на группы, а каждая
группа – на типы станков. По классификации,
разработанной экспериментальным
научно-исследовательским институтом
металлорежущих станков (ЭНИМС) все
станки подразделяются на девять групп
и девять типов (табл. 1.1).
1.1).
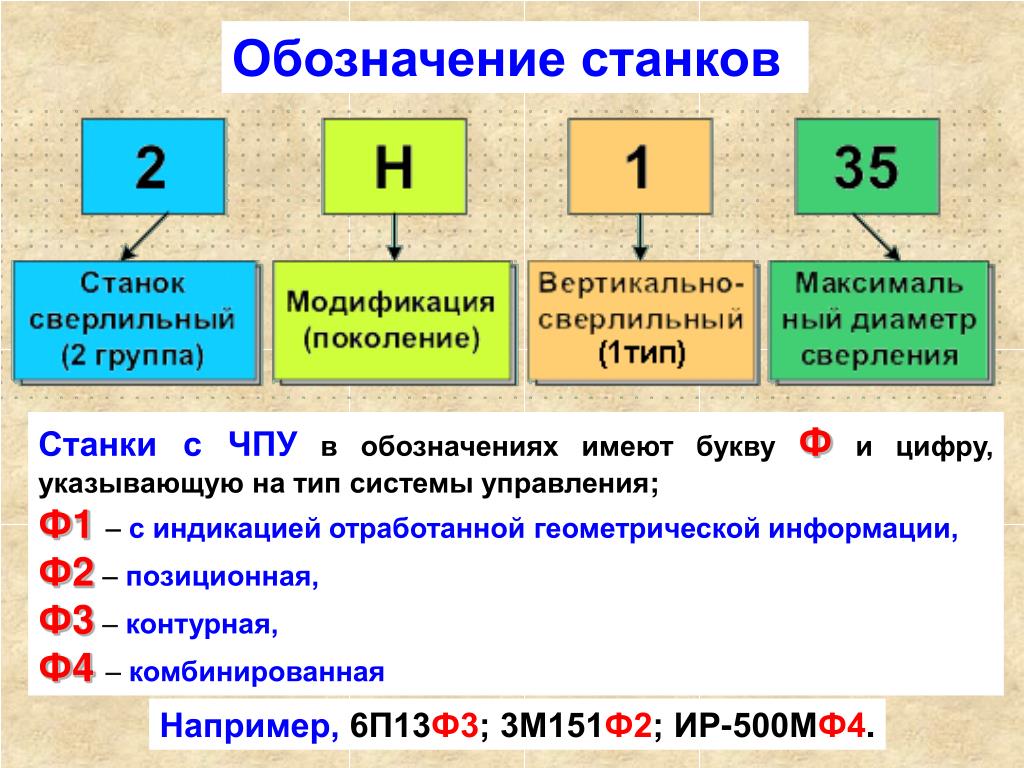
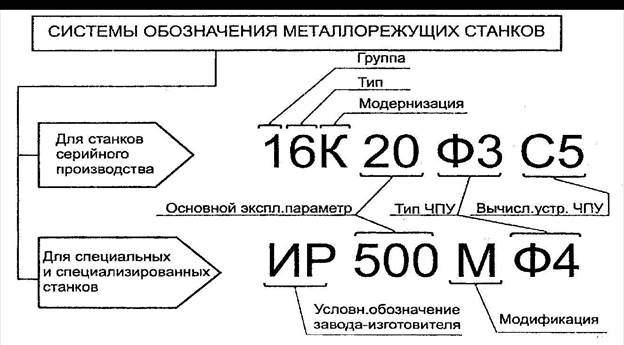
В соответствии с классификацией каждой модели станка присваивается соответствующий буквенно-цифровой шифр. Первая цифра обозначает группу станка, вторая – тип станка. Следующие цифры характеризуют габариты рабочего пространства: высота центров на токарных станках, максимально допустимый диаметр сверления для сверлильных станков и т.д.
Буква, стоящая после первой или второй цифры, означает модернизацию (улучшение) станка, буква стоящая после всех цифр указывает на модификацию (видоизменение) станка по сравнению с базовой моделью.
Например, 16К20 – относится к первой группе (токарные станки), к шестому типу (токарные и лобовые). 20-высота центров над станиной – 400 мм, К – модернизация станка.
2Н135 – вертикально-сверлильный станок с максимальным диаметром сверления 35мм, модернизированный по отношению к базовой модели 2135.
6Р82 –
горизонтально-фрезерный консольный
станок с типоразмером стола №2 (320×1250
мм), модернизированный.
6Р82Ш – модифицированный станок (по сравнению с предыдущей моделью имеет дополнительный шпиндель).
Станки с числовым программным управлением в конце обозначения модели имеют букву Ф: Ф2, Ф3, Ф4. Если в обозначении станка с ЧПУ, имеется буква Р, то станок оснащен револьверной головкой, если буква М – то инструментальным магазином.
Таблица 1.1
Классификация металлорежущих станков
Станки | Группа | Тип станка | ||||||||
2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
Токарные | 1 | Одношпин-дельные автоматы и полуавтоматы | Многошпин-дельные автоматы и полуавтоматы | Револьверные | Сверлильно-отрезные | Карусельные | Токарные и лобовые | Многорезцо-вые | Специализированные | Разные |
Сверлильные и расточные | 2 | Вертикально-сверлильные | Одношпин-дельные полуавтоматы | Многошпин-дельные полуавтоматы | Координатно-расточные | Радиально-сверлильные | Расточные | Алмазно-расточные | Горизонталь-но-сверлильные | Разные |
| 3 | Круглошли-фовальные | Внутришлифо-вальные | Обдирочно-шлифоваль-ные | Специализи-рованные шлифовальные | _ | Заточные | Плоско-шлифоваль-ные | Притирочные и полироваль-ные | Разные |
Комбинирован-ные и физико-химической обработки | 4 | Универсаль-ные | Полуавтоматы | Автоматы | Электрохи-мические | Электро-искровые | _ | Электро-эрозионные, ультразвуко-вые | Анодно-механические | _ |
Зубо- и резьбообрабатывающие | 5 | Зубодолбеж-ные для цилиндрических колес | Зуборезные для конических колес | Зубофрезер-ные для цилиндрических колес и шлицевых валов | Зубофрезер-ные для червячных колес | Для обработки торцов зубьев колес | Резьбофре-зерные | Зубоотделоч-ные | Зубо- и резьбошлифовальные | Разные |
Фрезерные | 6 | Вертикально-фрезерные консольные | Фрезерные непрерывного действия | Продольно-фрезерные одностоечные | Копироваль-ные и гравировальные | Вертикаль-ные бесконсольные | Продольно-фрезерные двухстоечные | Широкоуниверсальные | Горизонталь-но-фрезерные консольные | Разные |
Строгольные, долбежные, протяжные | 7 | Продольно-строгальные одностоечные | Продольно-строгальные двухстоечные | Поперечно-строгальные | Долбежные | Протяжные горизонталь-ные | _ | Пртяжные вертикальные | Разные | |
Разрезные | 8 | Правильно-отрезные | Ленточные пилы | Дисковые пилы | Ножовочные пилы | |||||
резцом | абразивным кругом | диском | ||||||||
Разные | 9 | Муфто- и трубообраба-тывающие | Пилонасека-тельные | Бесцентрово-обдирочные | Правильные | Для испыта-ния инструментов | Делитель-ные машины | Балансиро-вочны | ||
Специальные и
специализированные станки обозначаются
двумя буквами, присвоенному каждому из
станкостроительных заводов, и последующими
цифрами, характеризующими порядковый
номер станка.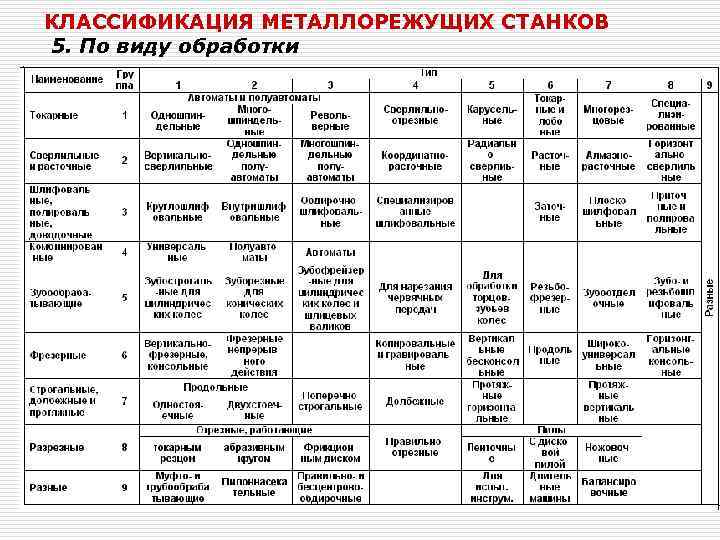
ВШ – Витебский станкостроительный завод. ВШ-031 – станок для затылования метчиков.
ОШ – Оршанский станкостроительный завод. ОШ-78- специальный плоскошлифовальный станок (для шлифования Т-образных пазов в корпусе токарных патронов).
В современных условиях наблюдается тенденция отхода от системы, разработанной ЭНИМС. В обозначениях моделей универсальных станков также присутствуют буквы, указывающие на производителя, как и при обозначении специальных и специализированных станков.
Обозначение – модель – станок
Cтраница 1
Обозначение модели станка состоит из сочетания трех или четырех цифр и букв. Первая цифра означает номер группы, вторая – номер подгруппы ( тип станка), а последние одна или две цифры – наиболее характерные технологические параметры станка. Например, 1Е116 означает токарно-револьверный одно-шпиндельный автомат с наибольшим диаметром обрабатываемого прутка 16 мм; 2Н125 означает вертикально-сверлильный станок с наибольшим условным диаметром сверления 25 мм.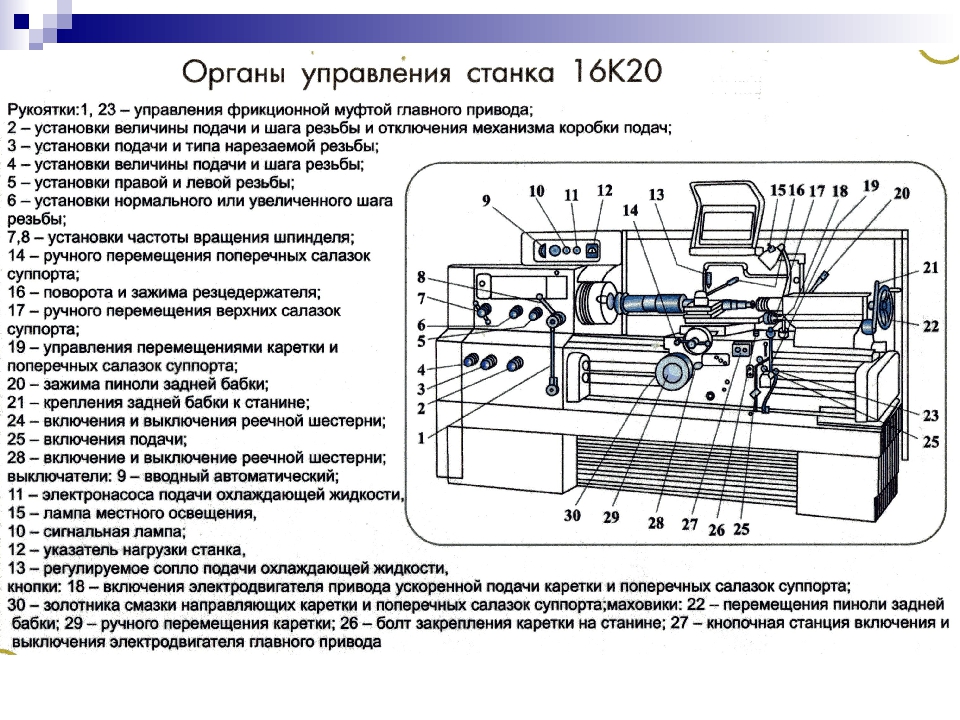 Буква, стоящая после первой цифры, указывает на различное исполнение и модернизацию основной базовой модели станка. Буква в конце цифровой части означает модификацию базовой модели, класс точности станка или его особенности.
[1]
Буква, стоящая после первой цифры, указывает на различное исполнение и модернизацию основной базовой модели станка. Буква в конце цифровой части означает модификацию базовой модели, класс точности станка или его особенности.
[1]
Обозначение модели станка состоит из сочетания трех или четырех цифр и букв. Первая цифра означает номер группы, вторая – номер подгруппы ( тип станка), а последние одна или две цифры – наиболее характерные технологические параметры станка. Например, 1ЕП6 означает токарно-револьверный одно-шпиндельный автомат с наибольшим диаметром обрабатываемого прутка 16 мм; 2Н125 означает вертикально-сверлильный станок с наибольшим условным диаметром сверления 25 мм. Буква, стоящая после первой цифры, указывает на различное исполнение и модернизацию основной базовой модели станка. Буква в конце цифровой части означает модификацию базовой модели, класс точности станка или его особенности. [2]
В обозначении модели станка первая цифра обозначает номер группы в той последовательности, как они перечислены.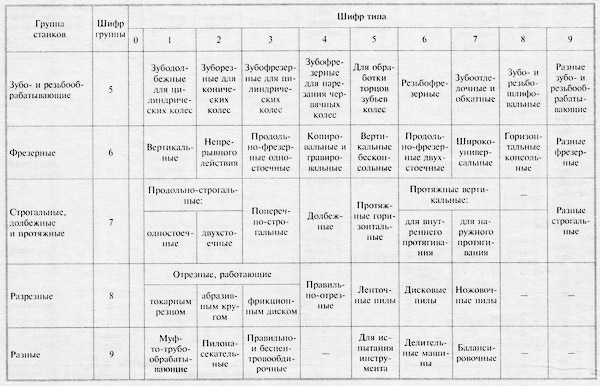 [3]
[3]
В обозначении модели токарно-револь-верного станка ( например, 1Е316П) последние две цифры ( 16) обозначают наибольший диаметр круглого прутка, обрабатываемого на данном станке. Размерный ряд револьверных станков, выпускаемых отечественными заводами, включает станки для обработки круглого прутка диаметром 10, 16, 25, 40, 65, 100 и 160 мм. Буква ( П) в конце цифрового обозначения модели станка указывает на его точность. [4]
Кроме цифр в обозначении модели станка имеются буквы. Если буква находится между первой и второй цифрами, это означает, что конструкция станка существенно усовершенствовалась по сравнению с прежней моделью. С 1984 г. его выпускают с обозначением 6Т82, несмотря на то, что основной показатель технической характеристики ( размер стола) остался без изменений. Таким образом, эта буква является обозначением последовательно выпускаемых поколений станков. [5]
Станок изготовляется налаженным на шлифование определенной детали; при этом к обозначению модели станка добавляется индекс Н с соответствующим порядковым номером наладки. [6]
[6]
Как определяются системы устройств числового программного управления ( УЧПУ) по обозначению модели станка с ПУ и какие виды УЧПУ используются. [7]
Как определяется вид устройства числового программного управления ( УЧПУ) по обозначению модели станка с ПУ и какие виды УЧПУ используются. [8]
Система нумерации ( условного обозначения) станков отечественного производства основана на присвоении каждой модели станка определенного номера. Обозначение модели станка состоит из трех ( или четырех) цифр, иногда с добавлением прописных букв, обозначающих дополнительную характеристику станка. [9]
| Схема базирования инструмента.| Варианты управления станком. [10] |
Такие системы ЧПУ применяются в основном на сверлильных и расточных станках. В обозначении модели станка с такими системами ЧПУ записывается в конце индекс Ф2 ( например: мод. [11]
[11]
| Схема базирования инструмента.| Варианты управления станком. [12] |
Такие системы ЧПУ применяются в основном на токарных и фрезерных станках. В обозначении модели станка с такими системами ЧПУ записывается индекс ФЗ ( например: мод. [13]
| Укрупненная структурная схема программируемого УЧПУ ( класса CNC. [14] |
Такими системами ЧПУ оснащаются в основном многоцелевые станки. В обозначении модели станка записывается индекс Ф4 ( например; мод. [15]
Страницы: 1 2
Модель машинного обучения и ее 8 различных типов
Современный мир ИТ все больше охватывает машинное обучение и искусственный интеллект. В результате все больше отраслей осознают преимущества того, что машины и компьютеры принимают решения относительно повторяющихся задач без участия человека, тем самым освобождая людей для выполнения более важных задач.
Доступны различные типы машинного обучения, но сегодня мы сосредоточимся на шаблонах или, точнее, на моделях машинного обучения. В этой статье определяются модели машин, их типы и характеристики, а также способы их сборки.
Итак, приготовьтесь ознакомиться с моделями машинного обучения. Эта статья расширит ваши знания в области машинного обучения, что пригодится, если вы подаете заявку на работу, связанную с машинным обучением. Кроме того, вы хотите уверенно отвечать на вопросы интервью по машинному обучению.
Что такое модель машинного обучения?
Прежде чем мы приступим к изучению моделей машинного обучения, давайте рассмотрим базовое определение машинного обучения. Машинное обучение — это ответвление искусственного интеллекта, которое анализирует данные и автоматизирует построение аналитических моделей. Машинное обучение говорит нам, что системы могут, если они обучены, выявлять закономерности, учиться на данных и принимать решения практически без вмешательства человека.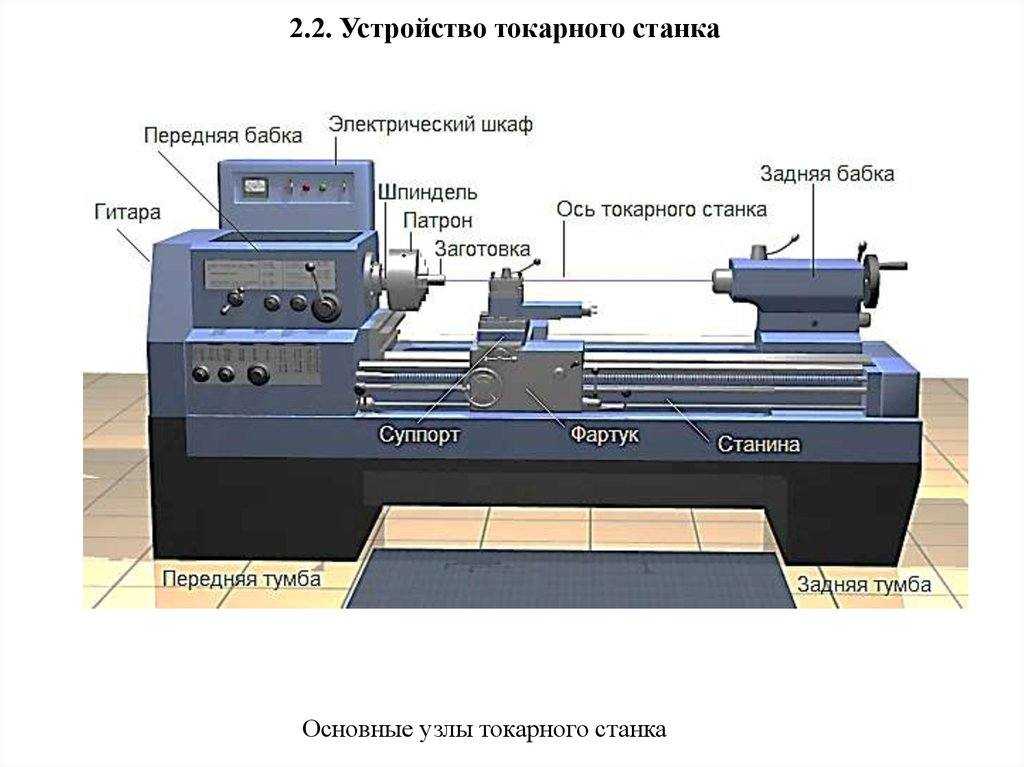
С другой стороны, модели машинного обучения — это файлы, обученные распознавать определенные типы шаблонов. Модели также известны как результат процесса обучения и считаются математическим представлением реальных процессов.
Специалисты по данным обучают модель набору данных, предоставляя ей необходимый алгоритм для рассуждений и извлечения уроков из данных. Во-первых, обучающие данные должны включать правильный ответ, также известный как «целевой атрибут» или просто «целевой». Затем алгоритм обучения ищет шаблоны в обучающих данных, которые сопоставляют соответствующие атрибуты данных с правильным ответом, также известным как цель. Затем алгоритм выводит модель машинного обучения, предназначенную для захвата этих шаблонов. Весь этот процесс является одним из наиболее важных этапов машинного обучения.
В конечном счете, эффективно обученная машинная модель может анализировать данные, с которыми она никогда раньше не сталкивалась, и делать прогнозы, связанные с этими данными, и все это без вмешательства человека. Например, вы можете обучить модель машинного обучения, чтобы предсказать, является ли электронное письмо законным или спамом. Специалист по обработке данных предоставит машинному обучению обучающие данные, содержащие метку, которая определяет, является ли электронное письмо спамом или законным. Затем машинная модель обучается предсказывать, будут ли будущие электронные письма спамом или нет.
Например, вы можете обучить модель машинного обучения, чтобы предсказать, является ли электронное письмо законным или спамом. Специалист по обработке данных предоставит машинному обучению обучающие данные, содержащие метку, которая определяет, является ли электронное письмо спамом или законным. Затем машинная модель обучается предсказывать, будут ли будущие электронные письма спамом или нет.
Типы моделей машинного обучения
Модели машинного обучения бывают разных версий, как и существует множество различных классификаций машинного обучения. Конечно, не все согласны с точным количеством или разбивкой моделей машинного обучения, но мы представляем два наиболее распространенных резюме.
Для начала некоторые люди разделяют модели машинного обучения на три типа:
Контролируемое обучение
Наборы данных включают желаемые результаты или метки, чтобы функция могла вычислить ошибку для любого данного прогноза. Часть контроля вступает в игру, когда создается прогноз, и возникает ошибка, чтобы изменить функцию и изучить отображение. Цель контролируемого обучения — создать функцию, которая эффективно обобщает данные, которые она никогда не видела.
Часть контроля вступает в игру, когда создается прогноз, и возникает ошибка, чтобы изменить функцию и изучить отображение. Цель контролируемого обучения — создать функцию, которая эффективно обобщает данные, которые она никогда не видела.
Бывают случаи, когда набор данных не дает желаемого результата, поэтому нет возможности контролировать функцию. Вместо этого процесс пытается сегментировать набор данных на «классы», чтобы каждый класс имел сегмент набора данных с общими функциями. Неконтролируемое обучение направлено на создание функции сопоставления, которая классифицирует данные на основе признаков, обнаруженных в данных.
При обучении с подкреплением алгоритм пытается изучить действия для заданного набора состояний, которые приводят к целевому состоянию. Таким образом, ошибки отмечаются не после каждого примера, а при получении сигнала подкрепления, например, при достижении целевого состояния. Этот процесс очень напоминает человеческое обучение, где обратная связь предоставляется не для каждого действия, а только тогда, когда ситуация требует вознаграждения.
В качестве альтернативы мы можем разделить модели машинного обучения на пять типов. Этот подход дает более конкретный и глубокий взгляд на характеристики машинного обучения.
Классификация предсказывает класс или тип объекта в соответствии с конечным числом вариантов. Выходная переменная классификации всегда является категорией. Например, это спам по электронной почте или нет?
Модели регрессии
Регрессия — это набор задач, в котором выходные переменные могут принимать непрерывные значения. Например, прогнозирование цены барреля нефти на товарном рынке — стандартная задача регрессии. Модели регрессии далее делятся на:
o Деревья решений
o Случайные леса
o Линейная регрессия
Кластеризация
Эта модель предполагает объединение похожих объектов в группы. Этот процесс помогает автоматически идентифицировать похожие объекты без вмешательства человека. Эффективным моделям машинного обучения с учителем, в том числе моделям, которые необходимо обучать на размеченных или отобранных вручную данных, нужны однородные данные, а кластеризация обеспечивает более разумный способ сделать это.
Эффективным моделям машинного обучения с учителем, в том числе моделям, которые необходимо обучать на размеченных или отобранных вручную данных, нужны однородные данные, а кластеризация обеспечивает более разумный способ сделать это.
Иногда количество возможных переменных в реальных наборах данных слишком велико, что приводит к проблемам. Не все эти бесчисленные переменные даже вносят существенный вклад в достижение цели. Таким образом, мы переходим к уменьшению размерности, которое сохраняет дисперсии с меньшим числом переменных.
Глубокое обучение
Этот тип машинного обучения использует нейронные сети. Нейронные сети — это сети математических уравнений. Сеть берет входные переменные, прогоняет их через уравнения и создает выходные переменные. Наиболее значимые модели глубокого обучения:
o Автоэнкодеры
o Машина Больцмана
o Сверточные нейронные сети
o Многослойный персептрон
o Рекуррентные нейронные сети
Как построить модель машинного обучения
Существует семь шагов для создания хорошей модели машинного обучения.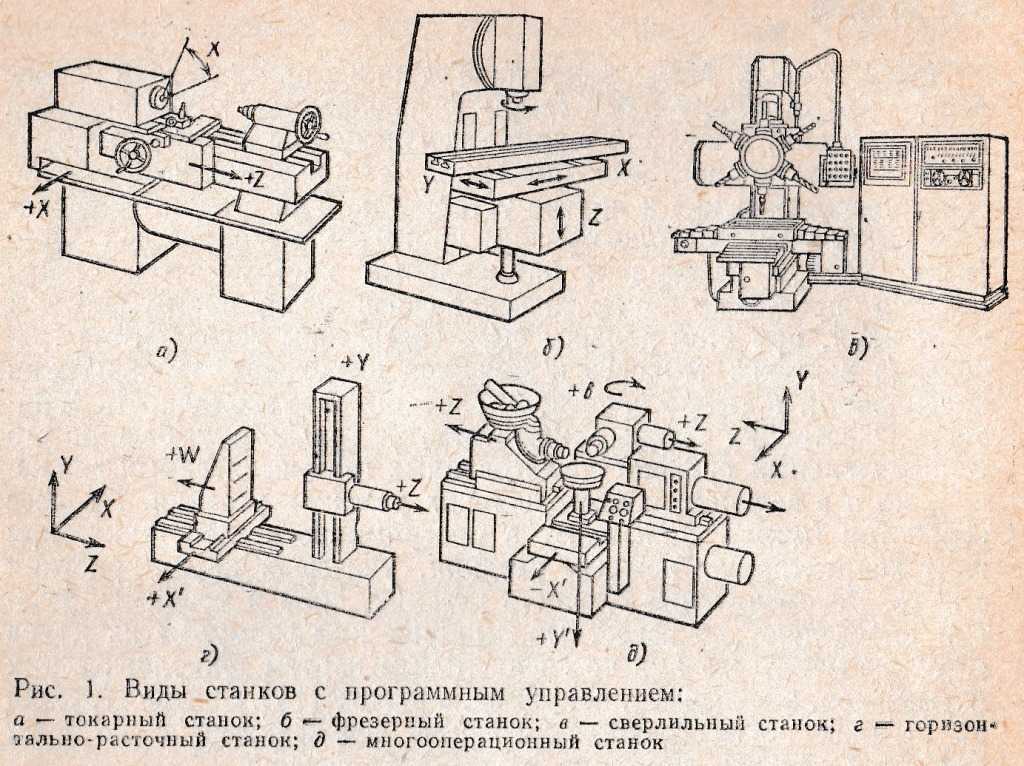
- Понимание бизнес-проблемы и того, что составляет успех. Вам нужно понять проблему, прежде чем вы сможете ее решить. Это понимание включает в себя работу с владельцем проекта и установление требований и целей. Затем выясните, какие части бизнес-цели нуждаются в решении для машинного обучения и как узнать, достигли ли вы успеха.
- Поймите данные и идентифицируйте их. Для обучения модели машинного обучения полагаются на чистые и многочисленные обучающие данные. Выясните, какие данные вам нужны и достаточно ли они подходят для проекта. Это помогло бы установить, откуда берутся данные, сколько вам нужно и в каком состоянии. Кроме того, вы должны понимать, как и будет ли модель машинного обучения работать с данными в реальном времени.
- Соберите и подготовьте данные. Теперь, когда вы знаете свои источники данных, вам нужно обработать данные во что-то подходящее для обучения машинному обучению. Этот процесс включает в себя сбор данных из многочисленных источников, их стандартизацию, поиск и замену ошибочной информации, удаление дублирующейся и лишней информации, а также разделение данных на наборы для обучения, тестирования и проверки.

- Обучите свою модель. Теперь самое интересное. Вы должны научить свою модель учиться на качественных данных, которые вы собрали и обработали. Этот шаг включает в себя выбор метода модели, обучение модели, выбор алгоритмов и оптимизацию модели. Обратитесь к типам моделей машинного обучения, упомянутым выше, для ваших вариантов.
- Оцените производительность модели и настройте тесты. Этот шаг аналогичен аспекту обеспечения качества разработки приложений. Вы должны оценить производительность своей модели в соответствии с установленными требованиями и показателями, которые, в свою очередь, определяют, насколько хорошо вы можете ожидать, что она будет работать в реальном мире.
- Попробуйте модель и убедитесь, что она работает должным образом. Этот шаг также известен как операционализация модели. Затем разверните модель таким образом, чтобы вы могли постоянно измерять и отслеживать ее производительность. Облачные среды идеально подходят для этого. Затем разработайте тесты, которые вы можете использовать для измерения будущих итераций вашей модели. Затем постоянно повторяйте различные аспекты вашей модели, чтобы улучшить ее общую производительность.
- Продолжайте корректировать и повторять свою модель. Продолжайте отслеживать и улучшать свою модель. В конце концов, технологии развиваются и меняются, бизнес-требования меняются, а реальный мир время от времени бросает вызов вещам. Любой из этих факторов потенциально может означать новые требования. Продолжайте улучшать точность и производительность модели. Думайте о своей модели машинного обучения как о мобильном приложении. Приложение всегда будет нуждаться в настройке, обновлении и улучшении. То же самое относится и к вашей модели машинного обучения.

 Затем разработайте тесты, которые вы можете использовать для измерения будущих итераций вашей модели. Затем постоянно повторяйте различные аспекты вашей модели, чтобы улучшить ее общую производительность.
Затем разработайте тесты, которые вы можете использовать для измерения будущих итераций вашей модели. Затем постоянно повторяйте различные аспекты вашей модели, чтобы улучшить ее общую производительность.Ускорьте свою карьеру в области искусственного интеллекта и машинного обучения с помощью программы последипломного образования по искусственному интеллекту и машинному обучению Университета Пердью в сотрудничестве с IBM.
Хотите сделать карьеру в области машинного обучения?
По мере роста популярности искусственного интеллекта и машинного обучения растет потребность в специалистах по машинному обучению. Simplilearn предлагает сертификацию AI ML, которая может дать старт новой интересной карьере, если эта область вас интересует.
Программа прикладного машинного обучения, проводимая совместно с Университетом Пердью, предназначена как для выпускников, так и для работающих профессионалов и включает в себя обучение мирового уровня, ориентированные на результат учебные лагеря и практические проекты. Программа охватывает такие концепции науки о данных и машинного обучения, как анализ данных, Python и обработка данных. Вы также изучите проектирование признаков, выбор признаков, статистику, моделирование временных рядов, контролируемое и неконтролируемое обучение, системы рекомендаций, ансамблевое обучение, дерево решений и случайный лес.
Компания Indeed сообщает, что инженеры по машинному обучению в США зарабатывают в среднем 150 660 долларов США в год. Кроме того, Payscale показывает, что инженеры машинного обучения в Индии зарабатывают в среднем 703 084 фунта стерлингов в год.
Кроме того, Payscale показывает, что инженеры машинного обучения в Индии зарабатывают в среднем 703 084 фунта стерлингов в год.
Сообщается, что инженеры по машинному обучению входят в десятку самых востребованных профессий в области искусственного интеллекта. Это карьерный путь, который предлагает отличные награды, интересные задачи, гарантии занятости и светлое будущее. Позвольте Simplilearn помочь вам сделать первые шаги к лучшему будущему. Ознакомьтесь со всеми нашими курсами по искусственному интеллекту и машинному обучению уже сегодня!
моделей машинного обучения | Топ-5 удивительных моделей машинного обучения
Модель машинного обучения является результатом процесса обучения и определяется как математическое представление реального процесса. Алгоритмы машинного обучения находят шаблоны в обучающем наборе данных, который используется для аппроксимации целевой функции и отвечает за сопоставление входных данных с выходными из доступного набора данных. Эти методы машинного обучения зависят от типа задачи и классифицируются как модели классификации, модели регрессии, кластеризация, уменьшение размерности, анализ главных компонентов и т. д.
Эти методы машинного обучения зависят от типа задачи и классифицируются как модели классификации, модели регрессии, кластеризация, уменьшение размерности, анализ главных компонентов и т. д.
Типы моделей машинного обучения
В зависимости от типа задач модели машинного обучения можно разделить на следующие типы:
- Классификационные модели
- Модели регрессии
- Кластеризация
- Уменьшение размерности
- Глубокое обучение и т. д.
1) Классификация
Применительно к машинному обучению классификация — это задача прогнозирования типа или класса объекта в рамках конечного числа вариантов. Выходная переменная для классификации всегда является категориальной переменной. Например, определение того, является ли электронное письмо спамом, является стандартной задачей бинарной классификации. Теперь давайте отметим некоторые важные модели для задач классификации.
- Алгоритм K-ближайших соседей — простой, но исчерпывающий в вычислительном отношении.
- Наивный Байес — основан на теореме Байеса.
- Логистическая регрессия — линейная модель для бинарной классификации.
- SVM — может использоваться для бинарной/мультиклассовой классификации.
- Дерево решений — ‘ If Else ’ Классификатор на основе, более устойчивый к выбросам.
- Ансамбли — комбинация нескольких моделей машинного обучения, объединенных вместе для получения лучших результатов.
2) Регрессия
В машине регрессия обучения представляет собой набор задач, в которых выходная переменная может принимать непрерывные значения. Например, прогнозирование стоимости авиабилетов можно рассматривать как стандартную задачу регрессии. Отметим некоторые важные модели регрессии, используемые на практике.
- Линейная регрессия — простейшая базовая модель для задачи регрессии, хорошо работает, только когда данные линейно разделимы и мультиколлинеарность очень мала или отсутствует.
- Регрессия Лассо — Линейная регрессия с регуляризацией L2.
- Регрессия хребта — линейная регрессия с регуляризацией L1.
- Регрессия SVM
- Регрессия дерева решений и т. д.

3) Кластеризация
Проще говоря, кластеризация — это задача группировки похожих объектов вместе. Это помогает идентифицировать похожие объекты автоматически без ручного вмешательства. Мы не можем создавать эффективные модели машинного обучения с учителем (модели, которые необходимо обучать с помощью отобранных вручную или помеченных данных) без однородных данных. Кластеризация помогает нам достичь этого более разумным способом. Ниже приведены некоторые из широко используемых моделей кластеризации:
- K означает — простой, но с высокой дисперсией.
- K означает++ — Модифицированная версия K означает.
- К медоиды.
- Агломеративная кластеризация — модель иерархической кластеризации.
- DBSCAN — алгоритм кластеризации на основе плотности и т. д.
4) Уменьшение размерности
Размерность — это количество переменных-предикторов, используемых для прогнозирования независимой переменной или цели. Часто в реальных наборах данных количество переменных слишком велико. Слишком много переменных также навлекают на модели проклятие переобучения. На практике среди этого большого количества переменных не все переменные в равной степени способствуют достижению цели, и в большом количестве случаев мы действительно можем сохранить дисперсии с меньшим количеством переменных. Перечислим некоторые часто используемые модели уменьшения размерности.
Часто в реальных наборах данных количество переменных слишком велико. Слишком много переменных также навлекают на модели проклятие переобучения. На практике среди этого большого количества переменных не все переменные в равной степени способствуют достижению цели, и в большом количестве случаев мы действительно можем сохранить дисперсии с меньшим количеством переменных. Перечислим некоторые часто используемые модели уменьшения размерности.
- PCA — создает меньшее количество новых переменных из большого количества предикторов. Новые переменные независимы друг от друга, но менее интерпретируемы.
- TSNE — обеспечивает встраивание точек данных более высокого измерения в более низкое измерение.
- SVD — Разложение по единственному значению используется для разложения матрицы на более мелкие части для эффективного расчета.
5) Глубокое обучение
Глубокое обучение — это подмножество машинного обучения, связанное с нейронными сетями. Основываясь на архитектуре нейронных сетей, давайте перечислим важные модели глубокого обучения:
- Многослойный персептрон
- Сверточные нейронные сети
- Рекуррентные нейронные сети
- Машина Больцмана
- Автоэнкодеры и т. д.
 д.
д.Какая модель лучше?
Выше мы рассмотрели множество моделей машинного обучения. Теперь нам приходит на ум очевидный вопрос: «Какая из этих моделей является лучшей?» Это зависит от рассматриваемой проблемы и других связанных с ней атрибутов, таких как выбросы, объем доступных данных, качество данных, проектирование признаков и т. д. всегда предпочтительнее начинать с самой простой модели, применимой к проблеме, и постепенно увеличивать сложность путем правильной настройки параметров и перекрестной проверки. В мире науки о данных есть пословица: «Перекрестная проверка заслуживает большего доверия, чем знание предметной области».
Как построить модель?
Давайте посмотрим, как построить простую модель логистической регрессии, используя библиотеку Python Scikit Learn. Для простоты мы предполагаем, что проблема представляет собой стандартную модель классификации, а «train.csv» — это поезд, а «test.csv» — данные поезда и теста соответственно.
Заключение
В этой статье обсуждались важные модели машинного обучения, используемые в практических целях, и как построить простую модель в Python.