Обозначение – модель – станок
Cтраница 1
Обозначение модели станка состоит из сочетания трех или четырех цифр и букв. Первая цифра означает номер группы, вторая – номер подгруппы ( тип станка), а последние одна или две цифры – наиболее характерные технологические параметры станка. Например, 1Е116 означает токарно-револьверный одно-шпиндельный автомат с наибольшим диаметром обрабатываемого прутка 16 мм; 2Н125 означает вертикально-сверлильный станок с наибольшим условным диаметром сверления 25 мм. Буква, стоящая после первой цифры, указывает на различное исполнение и модернизацию основной базовой модели станка. Буква в конце цифровой части означает модификацию базовой модели, класс точности станка или его особенности. [1]
Обозначение модели станка состоит из сочетания трех или четырех цифр и букв. Первая цифра означает номер группы, вторая – номер подгруппы ( тип станка), а последние одна или две цифры – наиболее характерные технологические параметры станка.
В обозначении модели станка первая цифра обозначает номер группы в той последовательности, как они перечислены. [3]
В обозначении модели токарно-револь-верного станка ( например, 1Е316П) последние две цифры ( 16) обозначают наибольший диаметр круглого прутка, обрабатываемого на данном станке. Размерный ряд револьверных станков, выпускаемых отечественными заводами, включает станки для обработки круглого прутка диаметром 10, 16, 25, 40, 65, 100 и 160 мм. Буква ( П) в конце цифрового обозначения модели станка указывает на его точность.
Кроме цифр в обозначении модели станка имеются буквы. Если буква находится между первой и второй цифрами, это означает, что конструкция станка существенно усовершенствовалась по сравнению с прежней моделью. С 1984 г. его выпускают с обозначением 6Т82, несмотря на то, что основной показатель технической характеристики ( размер стола) остался без изменений. Таким образом, эта буква является обозначением последовательно выпускаемых поколений станков. [5]
Станок изготовляется налаженным на шлифование определенной детали; при этом к обозначению модели станка добавляется индекс Н с соответствующим порядковым номером наладки. [6]
Как определяются системы устройств числового программного управления ( УЧПУ) по
Как определяется вид устройства числового программного управления ( УЧПУ) по обозначению модели станка с ПУ и какие виды УЧПУ используются. [8]
[8]
Система нумерации ( условного обозначения) станков отечественного производства основана на присвоении каждой модели станка определенного номера. Обозначение модели станка состоит из трех ( или четырех) цифр, иногда с добавлением прописных букв, обозначающих дополнительную характеристику станка. [9]
| Схема базирования инструмента.| Варианты управления станком. [10] |
Такие системы ЧПУ применяются в основном на сверлильных и расточных станках. В обозначении модели станка с такими системами ЧПУ записывается в конце индекс Ф2 ( например: мод. [11]
| Схема базирования инструмента.| Варианты управления станком. [12] |
Такие системы ЧПУ применяются в основном на токарных и фрезерных станках. В обозначении модели станка с такими системами ЧПУ записывается индекс ФЗ ( например: мод. [13]
[13]
| Укрупненная структурная схема программируемого УЧПУ ( класса CNC. [14] |
Такими системами ЧПУ оснащаются в основном многоцелевые станки. В обозначении модели станка записывается индекс Ф4 ( например; мод. [15]
Страницы: 1 2
Типы и обозначения МРС | Машиностроение
Основная классификация металлорежущих станков построена по технологическому признаку и подразделяются на 9 групп:
- Токарные станки, основным признаком которых является главное вращательное движение заготовки и поступательное движение подачи инструмента. На станках этой группы обрабатываются тела вращения.
- Сверлильные и расточные станки. Характерным признаком станков этой группы является главное вращательное движение инструмента. Поступательное движение подачи могут осуществлять как заготовка, так и инструмент. Станки предназначены в основном для обработки отверстий.

- Шлифовальные станки, основной характерной особенностью которых является применяемый абразивный инструмент.
- Комбинированные станки. Станки этой группы отличаются тем, что имеют на одной станине устройства, позволяющие производить точение, сверление, фрезерование, шлифование, а иногда строгание.
- Резьбо — и зубообрабатывающие станки. В эту группу выделены зубообрабатывающие и резьбообрабатывающие станки независимо от способа осуществления этих операций в силу общности кинематических особенностей.
- Фрезерные станки, основным признаком которых является применяемый инструмент — фреза, совершающая главное вращательное движение. Станки применяются для обработки плоскостей и фасонных поверхностей.
- Строгальные и протяжные станки. В эту группу сконцентрированы станки с главным поступательным движением. Строгальные станки предназначены для обработки плоскостей и фасонных линейчатых поверхностей, а протяжные — для обработки линейчатых поверхностей, определяемых формой режущей кромки инструмента — протяжки.
- Разрезные станки, предназначенные для отрезки заготовок от целого куска металла.
- Разные станки.


Внутри каждой группы станки подразделяются на 9 подгрупп т.е. на типы станков по более узким технологическим и конструктивным признакам. При изучении станков соответствующих групп эта классификация будет раскрыта.
По степени универсальности станки подразделяются на станки:
- общего назначения,
- специализированные,
- специальные.
Станки общего назначения (универсальные, широкоуниверсальные) позволяют обработку широкой номенклатуры деталей и применяются преимущественно в единичном и мелкосерийном производстве.
Специализированные станки предназначаются для обработки ограниченной номенклатуры деталей. Область их применения — серийное производство.
Специальные станки изготавливаются для обработки одного или весьма ограниченного числа наименований деталей или даже выполнения одной операции при обработке какой-либо детали.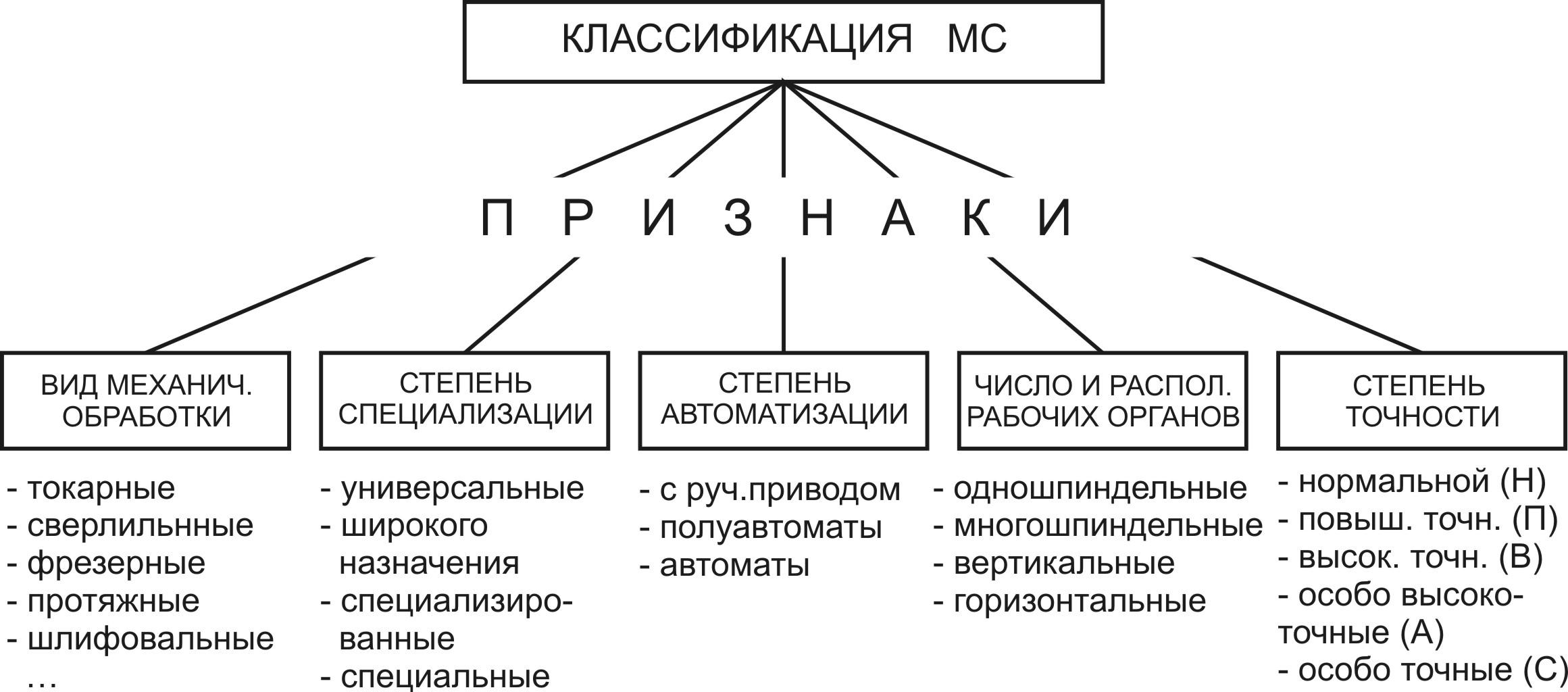 Эти станки применяются в массовом производстве.
Эти станки применяются в массовом производстве.
По точности станки подразделяются на пять классов:
Н — нормальной; П — повышенной; В — высокой; А — особо высокой точности; С — спец-мастер станки.
По массе различают:
- легкие — до 1 тонны,
- средние — 1…10 тонн,
- тяжелые — свыше 10 тонн.
Тяжелые подразделяются:
- на крупные — 10…30 тонн,
- собственно тяжелые — 30…100 тонн,
- уникальные — свыше 100 тонн.
Обозначения станков
Обозначения станков строятся на буквенно-цифровой основе. При обозначении станков общего назначения первая цифра показывает принадлежность к группе классификации. Вторая цифра определяет отношение станка к соответствующей подгруппе, типу, последняя или две последние цифры обозначают размерную характеристику станка. Буквы русского алфавита, размещаемые между цифрами, указывают на соответствующую модификацию станка данного типоразмера.
Буквы русского алфавита, размещаемые между цифрами, указывают на соответствующую модификацию станка данного типоразмера.
Например,
Обозначения станков-маркировка
В обозначениях специальных станков первые буквы указывают на индекс завода — изготовителя, а следующие за ними цифры — порядковый номер модели. Например, Е3-24 — станок Егорьевского завода «Комсомолец».
Прецизионные станки обозначаются соответствующей буквой в конце, например, 1И611П, 1К62В.
Станки с ЧПУ в обозначениях имеют букву Ф и цифру, указывающую на тип системы управления (1 — с индикацией отработанной геометрической информации, 2 — позиционная, 3 — контурная, 4 — комбинированная) например, 6П13Ф3; 3М151Ф2; ИР-500МФ4.
Что такое модели машинного обучения?
Что такое модель машинного обучения?
Модель машинного обучения — это программа, которая может находить закономерности или принимать решения на основе ранее неизвестного набора данных. Например, при обработке естественного языка модели машинного обучения могут анализировать и правильно распознавать намерения, стоящие за ранее неизвестными предложениями или сочетаниями слов.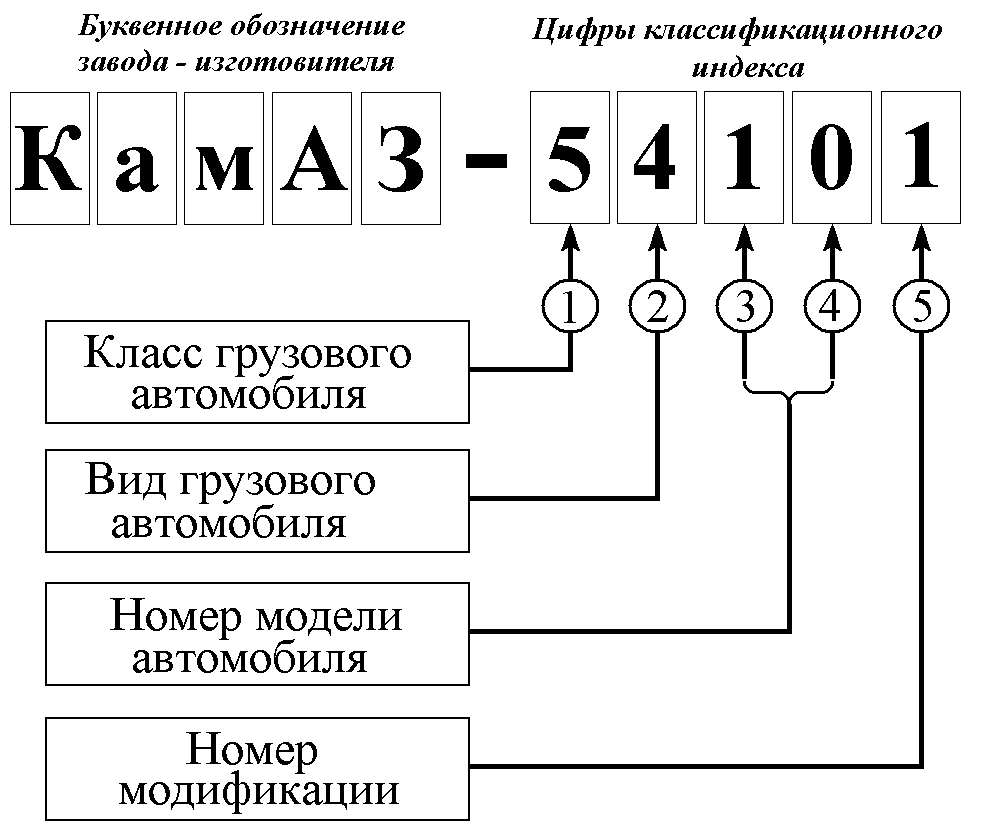 В распознавании изображений модель машинного обучения можно научить распознавать объекты, например автомобили или собак. Модель машинного обучения может выполнять такие задачи, «обучив» ее на большом наборе данных. Во время обучения алгоритм машинного обучения оптимизируется для поиска определенных закономерностей или выходных данных из набора данных в зависимости от задачи. Результат этого процесса — часто компьютерная программа с определенными правилами и структурами данных — называется моделью машинного обучения.
В распознавании изображений модель машинного обучения можно научить распознавать объекты, например автомобили или собак. Модель машинного обучения может выполнять такие задачи, «обучив» ее на большом наборе данных. Во время обучения алгоритм машинного обучения оптимизируется для поиска определенных закономерностей или выходных данных из набора данных в зависимости от задачи. Результат этого процесса — часто компьютерная программа с определенными правилами и структурами данных — называется моделью машинного обучения.
Что такое алгоритм машинного обучения?
Алгоритм машинного обучения — это математический метод поиска закономерностей в наборе данных. Алгоритмы машинного обучения часто основаны на статистике, исчислении и линейной алгебре. Некоторые популярные примеры алгоритмов машинного обучения включают линейную регрессию, деревья решений, случайный лес и XGBoost.
Что такое модельное обучение в машинном обучении?
Процесс запуска алгоритма машинного обучения на наборе данных (называемом обучающими данными) и оптимизации алгоритма для поиска определенных шаблонов или выходных данных называется обучением модели. Полученная функция с правилами и структурами данных называется обученной моделью машинного обучения.
Полученная функция с правилами и структурами данных называется обученной моделью машинного обучения.
Какие существуют типы машинного обучения?
В целом, большинство методов машинного обучения можно разделить на обучение с учителем, обучение без учителя и обучение с подкреплением.
Что такое контролируемое машинное обучение?
В машинном обучении с учителем алгоритму предоставляется набор входных данных, и он вознаграждается или оптимизируется для соответствия набору определенных выходных данных. Например, контролируемое машинное обучение широко используется в распознавании изображений с использованием метода, называемого классификацией. Контролируемое машинное обучение также используется для прогнозирования демографических показателей, таких как рост населения или показатели здоровья, с использованием метода, называемого регрессией.
Что такое неконтролируемое машинное обучение?
При неконтролируемом машинном обучении алгоритму предоставляется входной набор данных, но он не вознаграждается и не оптимизируется для конкретных выходных данных, а вместо этого обучается группировать объекты по общим характеристикам. Например, механизмы рекомендаций в интернет-магазинах основаны на неконтролируемом машинном обучении, в частности на методе, называемом кластеризацией.
Например, механизмы рекомендаций в интернет-магазинах основаны на неконтролируемом машинном обучении, в частности на методе, называемом кластеризацией.
Что такое обучение с подкреплением?
При обучении с подкреплением алгоритм обучается с помощью множества экспериментов методом проб и ошибок. Обучение с подкреплением происходит, когда алгоритм постоянно взаимодействует с окружающей средой, а не полагается на обучающие данные. Один из самых популярных примеров обучения с подкреплением — автономное вождение.
Какие существуют модели машинного обучения?
Существует множество моделей машинного обучения, и почти все они основаны на определенных алгоритмах машинного обучения. Популярные алгоритмы классификации и регрессии подпадают под контролируемое машинное обучение, а алгоритмы кластеризации обычно развертываются в сценариях неконтролируемого машинного обучения.
Контролируемое машинное обучение
- Логистическая регрессия: логистическая регрессия используется для определения принадлежности входных данных к определенной группе или нет
- SVM: SVM или машины опорных векторов создают координаты для каждого объекта в n-мерном пространстве и используют гиперплоскость для группировки объектов по общим признакам классифицировать объекты на основе признаков
- Деревья решений: Деревья решений также являются классификаторами, которые используются для определения того, к какой категории относятся входные данные, путем обхода листьев и узлов дерева
- Линейная регрессия: Линейная регрессия используется для выявления взаимосвязей между интересующей переменной и входными данными и прогнозирования ее значений на основе значений входных переменных.
- kNN: метод k ближайших соседей включает в себя группировку ближайших объектов в наборе данных и поиск наиболее часто встречающихся или средних характеристик среди объектов.
- Случайный лес: Случайный лес — это набор множества деревьев решений из случайных подмножеств данных, в результате чего комбинация деревьев может быть более точной в прогнозировании, чем одно дерево решений.
- Алгоритмы повышения: Алгоритмы повышения, такие как Gradient Boosting Machine, XGBoost и LightGBM, используют ансамблевое обучение. Они объединяют прогнозы нескольких алгоритмов (например, деревьев решений) с учетом ошибки предыдущего алгоритма.

Неконтролируемое машинное обучение
- K-средних: Алгоритм K-средних находит сходство между объектами и группирует их в K различных кластеров.
- Иерархическая кластеризация: Иерархическая кластеризация строит дерево вложенных кластеров без указания количества кластеров.

Что такое дерево решений в машинном обучении (ML)?
Дерево решений — это прогностический подход в машинном обучении для определения того, к какому классу принадлежит объект. Как следует из названия, дерево решений представляет собой древовидную блок-схему, в которой класс объекта определяется шаг за шагом с использованием определенных известных условий. Дерево решений, визуализированное в домике у озера Databricks. Источник: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Что такое регрессия в машинном обучении?
Регрессия в науке о данных и машинном обучении — это статистический метод, который позволяет прогнозировать результаты на основе набора входных переменных. Результат часто является переменной, которая зависит от комбинации входных переменных. Модель линейной регрессии, выполненная на Databricks Lakehouse. Источник: https://www. databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Что такое классификатор в машинном обучении?
Классификатор — это алгоритм машинного обучения, который присваивает объекту членство в категории или группе. Например, классификаторы используются для определения того, является ли электронное письмо спамом или является ли транзакция мошеннической.
Сколько моделей существует в машинном обучении?
Много! Машинное обучение — это развивающаяся область, и всегда разрабатываются новые модели машинного обучения.
Какая модель лучше всего подходит для машинного обучения?
Модель машинного обучения, наиболее подходящая для конкретной ситуации, зависит от желаемого результата. Например, чтобы предсказать количество покупок автомобилей в городе на основе исторических данных, наиболее полезным может быть такой метод обучения с учителем, как линейная регрессия. С другой стороны, чтобы определить, купит ли потенциальный клиент в этом городе автомобиль, учитывая его доход и историю поездок на работу, лучше всего подойдет дерево решений.
Что такое развертывание модели в машинном обучении (ML)?
Развертывание модели — это процесс предоставления модели машинного обучения для использования в целевой среде — для тестирования или производства. Модель обычно интегрируется с другими приложениями в среде (такими как базы данных и пользовательский интерфейс) через API. Развертывание — это этап, после которого организация может окупить огромные инвестиции, сделанные в разработку модели. Полный жизненный цикл модели машинного обучения в Databricks Lakehouse. Источник: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Что такое модели глубокого обучения?
Модели глубокого обучения — это класс моделей машинного обучения, которые имитируют то, как люди обрабатывают информацию. Модель состоит из нескольких уровней обработки (отсюда и термин «глубокий») для извлечения признаков высокого уровня из предоставленных данных. Каждый уровень обработки передает более абстрактное представление данных на следующий уровень, а последний уровень обеспечивает более человеческое понимание. В отличие от традиционных моделей машинного обучения, которые требуют маркировки данных, модели глубокого обучения могут обрабатывать большие объемы неструктурированных данных. Они используются для выполнения более похожих на человека функций, таких как распознавание лиц и обработка естественного языка. Упрощенное представление глубокого обучения. Источник: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Каждый уровень обработки передает более абстрактное представление данных на следующий уровень, а последний уровень обеспечивает более человеческое понимание. В отличие от традиционных моделей машинного обучения, которые требуют маркировки данных, модели глубокого обучения могут обрабатывать большие объемы неструктурированных данных. Они используются для выполнения более похожих на человека функций, таких как распознавание лиц и обработка естественного языка. Упрощенное представление глубокого обучения. Источник: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Что такое машинное обучение временных рядов?
Модель машинного обучения с временными рядами — это модель, в которой одной из независимых переменных является последовательная продолжительность минут, дней, лет и т. д.), и она оказывает влияние на зависимую или прогнозируемую переменную. Модели машинного обучения временных рядов используются для прогнозирования событий с привязкой ко времени, например погоды на будущей неделе, ожидаемого количества клиентов в будущем месяце, прогноза доходов на будущий год и т. д.
д.
Где я могу узнать больше о машинном обучении?
- Ознакомьтесь с этой бесплатной электронной книгой, чтобы узнать о многих увлекательных примерах использования машинного обучения, которые внедряются предприятиями по всему миру.
- Чтобы получить более глубокое представление о машинном обучении от экспертов, ознакомьтесь с блогом Databricks Machine Learning.
Модели машинного обучения: что это такое и как их создавать
Модели машинного обучения имеют решающее значение для всего, от науки о данных до маркетинга, финансов, розничной торговли и многого другого. Сегодня есть несколько отраслей, не затронутых революцией машинного обучения, которая изменила не только то, как работают предприятия, но и целые отрасли.
Но что такое модели машинного обучения? И как они строятся?
В этой статье вы узнаете, как создаются модели машинного обучения, и найдете список популярных алгоритмов, лежащих в их основе. Вы также найдете рекомендуемые курсы и статьи, которые помогут вам освоить машинное обучение.
Что такое модель машинного обучения?
Модели машинного обучения — это компьютерные программы, которые используются для распознавания шаблонов в данных или для прогнозирования.
Модели машинного обучения создаются на основе алгоритмов машинного обучения, которые обучаются с использованием размеченных, неразмеченных или смешанных данных. Разные алгоритмы машинного обучения подходят для разных целей, таких как классификация или прогнозное моделирование, поэтому специалисты по данным используют разные алгоритмы в качестве основы для разных моделей. Когда данные вводятся в определенный алгоритм, они модифицируются для лучшего управления конкретной задачей и становятся моделью машинного обучения.
Например, дерево решений — это общий алгоритм, используемый как для классификации, так и для прогнозного моделирования. Ученый, работающий с данными, который хочет создать модель машинного обучения, которая идентифицирует различные виды животных, может обучить алгоритм дерева решений с различными изображениями животных. Со временем алгоритм будет изменяться в зависимости от данных и становиться все лучше в классификации изображений животных. В свою очередь, это в конечном итоге станет моделью машинного обучения.
Со временем алгоритм будет изменяться в зависимости от данных и становиться все лучше в классификации изображений животных. В свою очередь, это в конечном итоге станет моделью машинного обучения.
Подробнее: Деревья решений в машинном обучении: два типа (+ примеры)
Как построить модель машинного обучения
Модели машинного обучения создаются алгоритмами обучения либо с помеченными, либо с немаркированными данными, либо с их сочетанием. В результате существует три основных способа обучения и создания алгоритма машинного обучения:
Обучение с учителем: Обучение с учителем происходит, когда алгоритм обучается с использованием «помеченных данных» или данных, помеченных меткой, поэтому что алгоритм может успешно учиться на нем. Обучение алгоритма с помеченными данными помогает конечной модели машинного обучения узнать, как классифицировать данные в соответствии с пожеланиями исследователя.
Обучение без учителя: Обучение без учителя использует немаркированные данные для обучения алгоритма.
В этом процессе алгоритм находит закономерности в самих данных и создает свои собственные кластеры данных. Неконтролируемое обучение полезно для исследователей, которые хотят найти закономерности в данных, которые в настоящее время им неизвестны.
 В этом процессе алгоритм находит закономерности в самих данных и создает свои собственные кластеры данных. Неконтролируемое обучение полезно для исследователей, которые хотят найти закономерности в данных, которые в настоящее время им неизвестны.
В этом процессе алгоритм находит закономерности в самих данных и создает свои собственные кластеры данных. Неконтролируемое обучение полезно для исследователей, которые хотят найти закономерности в данных, которые в настоящее время им неизвестны.Подробнее : 7 алгоритмов машинного обучения, которые нужно знать
Загрузка…
Контролируемое и неконтролируемое машинное обучение
Advanced Machine Learning and Signal Processing
IBM Заполненная звезда Заполненная звезда Заполненная звезда Заполненная звезда Полузаполненная звезда4,5 (1208 оценок)
|
43 000 студентов зачислены
Курс 2 из 4 по углубленному изучению данных со специализацией IBM
Зарегистрироваться бесплатно
Что такое параметры машинного обучения?
Прежде чем исследователь обучит алгоритм машинного обучения, он должен сначала установить 90 129 гиперпараметров 9.0130 для алгоритма, которые действуют как внешние направляющие, указывающие, как алгоритм будет учиться.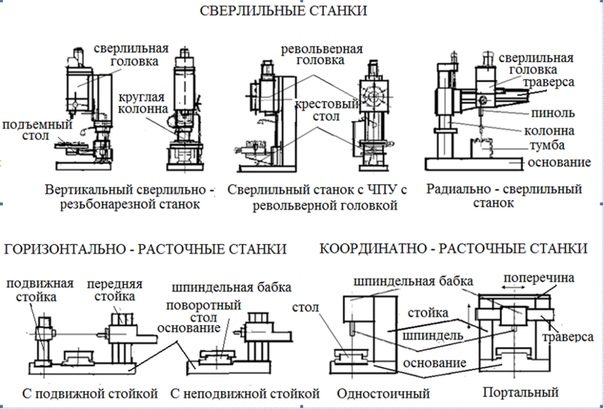 Например, количество ветвей в дереве решений, скорость обучения и количество кластеров в алгоритме кластеризации — все это примеры гиперпараметров.
Например, количество ветвей в дереве решений, скорость обучения и количество кластеров в алгоритме кластеризации — все это примеры гиперпараметров.
Поскольку алгоритм обучается и управляется гиперпараметрами, параметры начинают формироваться в ответ на обучающие данные. Эти параметры включают веса и смещения, формируемые алгоритмом по мере его обучения. Окончательные параметры модели машинного обучения называются параметров модели, , которые идеально соответствуют набору данных без превышения или уменьшения.
В то время как параметры модели машинного обучения могут быть идентифицированы, гиперпараметры, используемые для ее создания, не могут быть идентифицированы.
Загрузка…
Параметры и гиперпараметры
Нейронные сети и глубокое обучение
DeepLearning.AI Заполненная звездаЗаполненная звездаЗаполненная звездаЗаполненная звездаЗаполненная звезда4,9 (118 492 оценок) 90 005
|
Зачислено 1,2 млн студентов
Курс 1 из 5 специализации глубокого обучения
Зарегистрируйтесь бесплатно
Типы моделей машинного обучения
В машинном обучении преобладают два типа задач: классификация и прогнозирование.
Эти проблемы решаются с использованием моделей, полученных на основе алгоритмов, разработанных либо для классификации, либо для регрессии (метод, используемый для прогнозного моделирования). Иногда один и тот же алгоритм можно использовать для создания моделей классификации или регрессии, в зависимости от того, как он обучен.
Ниже вы найдете список общих алгоритмов, используемых для создания моделей классификации и регрессии.
Модели классификации
Логистическая регрессия
Наивный Байес
Деревья решений
- 90 004 Случайный лес
K-ближайший сосед (KNN)
Метод опорных векторов
Регрессионные модели
Подробнее о машинном обучении
Независимо от того, хотите ли вы стать специалистом по данным или просто хотите углубить свои знания о нейронных сетях, зачисление на онлайн-курс поможет вам продвинуться по карьерной лестнице.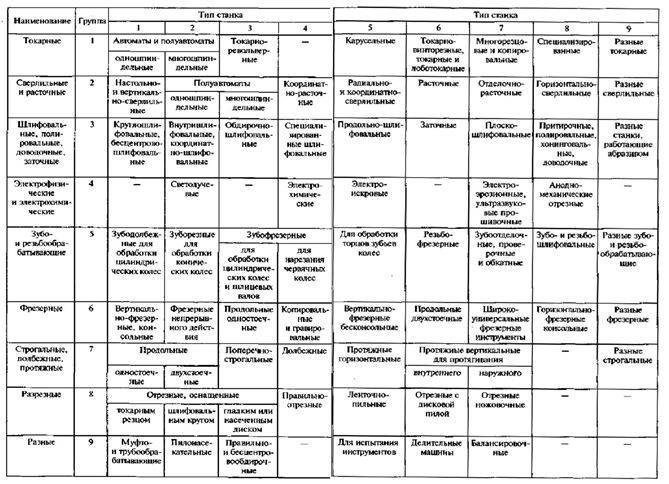
В Стэнфорде и специализации DeepLearning.AI по машинному обучению вы освоите фундаментальные концепции искусственного интеллекта и разовьете практические навыки машинного обучения в удобной для начинающих программе из трех курсов, разработанной провидцем в области искусственного интеллекта Эндрю Нг.
Тем временем специализация глубокого обучения DeepLearning.AI научит вас создавать и обучать архитектуру нейронной сети и вносить свой вклад в разработку передовых технологий искусственного интеллекта.
специализация
Машинное обучение
#BreakIntoAI со специализацией по машинному обучению. Овладейте фундаментальными концепциями искусственного интеллекта и отработайте практические навыки машинного обучения в удобной для начинающих программе из трех курсов, подготовленной провидцем в области искусственного интеллекта Эндрю Нг. Среднее время: 3 месяца
Учитесь в своем собственном темпе
Навыки, которые вы приобретете:
Деревья решений, искусственная нейронная сеть, логистическая регрессия, рекомендательные системы, линейная регрессия, регуляризация для предотвращения переобучения, градиентный спуск, обучение с учителем, логистическая регрессия для классификации, Xgboost, Tensorflow, ансамбли деревьев, советы по разработке моделей, совместная фильтрация, обучение без учителя , Обучение с подкреплением, Обнаружение аномалий
Автор: Coursera • Обновлено