шабрение направляющих “старика 625-го” – Ремонт и восстановление станков (общие вопросы)
Так же покатал по плоской направляющей, результат удивил, наоборот бугор по середине в районе десятки, как так- призматическая направляющая-по середине провал, плоская наоборот -бугор?
это говорит об износе направляющих под заднюю бабку и невыставленной станине перед промером….
вначале изготовить “мостик” для контроля направляющих и выставить,по возможности, станину(свести к минимуму спиральную извернутость)…
затем промер направляющих ЗБ. используем “мостик” , уровень, магн.стойку и линейку ..обрати внимание, что возле плоской направляющей под ЗБ расположена неработающая плоская направляющая, её(после проверки линейкой) можно принять за базу и использовать для контроля износа плоской направляющей ЗБ при помощи индикатора со стойкой и “мостика”.
направляющими каретки стоит заняться после восстановления станины.. (сам делаю так) выставить на домкратиках каретку с прикрученным фартуком…(соосность ходового винта и вала к валам(отверстиям)коробки подач и заднего кронштейна,зацепление вала-шестерни и рейки)….
переворачиваем каретку и на домкратики ложим подходяший вал(скалку)….замеряем зазор между валом и поверхностями направляющих щупами…шлифмашинкой “шабрим”….. или обкатываем вал на столе фрезерного станка в двух плоскостях ,закрепляем и фрезеруем…….
наделки ,думаю,стоит оставить латунные(выровнять ,приклеить,отшабрить)
Изменено 10.2013 05:32 ” data-short=”8 г”>13 октября, 2013 пользователем Z ANDREY
10.2013 05:32 ” data-short=”8 г”>13 октября, 2013 пользователем Z ANDREYНаправляющие и компенсаторы – Слесарно-механосборочные работы
Направляющие и компенсаторы
Категория:
Слесарно-механосборочные работы
Направляющие и компенсаторы
Поступательно движущиеся детали, перемещаясь, скользят по поверхности других деталей. Поверхности, по которым скользят подвижные части, называют направляющими. В зависимости от назначения направляющие могут иметь различную форму. Наиболее распространенные формы направляющих: плоская (или прямоугольного профиля), призматического профиля, в виде ласточкина хвоста (или трапецеидального профиля), круглая.
Станины металлорежущих станков, молотов и паровых машин обычно имеют плоские, призматические или V-образные направляющие. Направляющие в виде ласточкина хвоста применяют на суппортах и столах металлорежущих станков, ползунах и т. д.
Пригонка направляющих с сопрягаемыми деталями — трудоемкая операция и требует высокой точности. Чтобы облегчить регулирование трущихся поверхностей, применяют специальные устройства — компенсаторы.
Чтобы облегчить регулирование трущихся поверхностей, применяют специальные устройства — компенсаторы.
Компенсаторы бывают прямоугольные, косоугольные и клиновые с уклоном от 1:40 до 1:100. Планки 1 для регулирования зазора и клинья перемещаются в продольном направлении и удерживаются на установленном месте винтами. Регулирующую планку или клин, как правило, ставят с ненагруженной стороны подвижной детали.
Рис. 1. Регулирующие устройства (компенсаторы): а, б — планки, в, г, д, е — клинья
Сборка сборочных единиц с поступательно движущимися деталями в основном сводится к отделке направляющих и пригонке по ним поступательно движущихся деталей.
Применяют следующие способы отделки поверхностей поступательно движущихся деталей: шабрение, чистовое строгание широкими резцами и наведение «мороза», шлифование, притирка.
Шабрение направляющих — очень трудоемкая операция, поэтому там, где позволяют условия, его заменяют шлифованием.
Ниже рассмотрено шабрение поступательно движущихся частей токарно-винторезного станка с длиной направляющих более 3 м.
Плоскости, которые необходимо пригонять и отделывать, должны отвечать классам точности и конкретной модели станка.
Перед шабрением станину устанавливают на массивное основание и выверяют в продольном и поперечном направлении по уровню.
Рис. 2. Станина токарного станка с суппортом: 1 — поверхность под резцедержатель, 2 — поперечные салазки, 3 — направляющие поперечных салазок, 4, 7, 13 — поверхности суппорта, сопрягающиеся со станиной, 8, 10 — направляющие под заднюю бабку, 5, 6, 12 — верхние направляющие под прижимные планки суппорта, 9,11 — нижние направляющие под прижимные планки суппорта, 14 — клин поперечных салазок, 15 —18 — поперечные направляющие суппорта
Шабрение начинают с базовых поверхностей. Базовые поверхности выбирают так, чтобы по ним можно было шабрить и контролировать все остальные направляющие, а также пригонять и устанавливать суппорт, переднюю и заднюю бабки.
В рассмотренном примере наиболее удобной базой для шабрения будут направляющие под суппорт. Направляющие станины проверяют на краску линейкой и специальной плитой, профиль рабочей поверхности которой соответствует профилю отделываемых направляющих. На верху плиты находится контрольная площадка, параллельная горизонтальному участку рабочей поверхности, на которую ставят уровень.
Направляющие станины проверяют на краску линейкой и специальной плитой, профиль рабочей поверхности которой соответствует профилю отделываемых направляющих. На верху плиты находится контрольная площадка, параллельная горизонтальному участку рабочей поверхности, на которую ставят уровень.
Рис. 3. Схема пробивки маяков на направляющей каретки: 1,4 — направляющие каретки, 2 — плита для шабрения, 3 — уровень
Реклама:
Читать далее:
Пробивка маяков на направляющих
Статьи по теме:
Ремонт направляющих станин станка методом шабрения.
Станина устанавливается на стенде или на жестком фундаменте. В поперечном направлении выверяется по поверхности для крепления коробки подач с помощью рамного уровня. Это позволяет в дальнейшем ремонте суппорта легко определять перпендикулярность поверхностей: для крепления фартука на каретке суппорта к поверхности, для крепления коробки подач к станине. Горизонтальность направляющих определяется по уровню.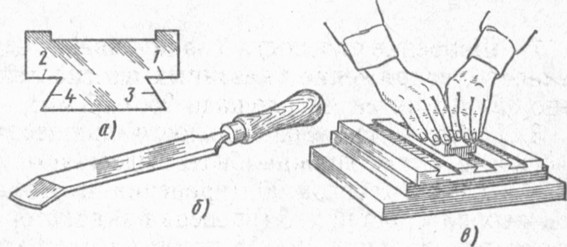
Особенностью данного типового технологического процесса ремонта (ТПР) является то, что при ремонте направляющих под заднюю бабку на длине 200-300 мм на конце станины за базу принимают поверхность крепления рейки. Эти поверхности никогда не изнашиваются и находятся в одной плоскости с поверхностями для крепления коробки подач и кронштейна ходового вала.
Восстановление параллельности направляющих станины к указанным поверхностям сокращает трудоемкость выверки параллельности осей ходового вала и ходового вала к направляющим станины.
Очень важным при капитальном ремонте квартиры является установка натяжных потолков. Я нашел натяжные потолки по низким ценам на сайте natyazhnyie-potolki.ru. Быстро приехали и установили очень красивый и качественный потолок. Поэтому если вы ищете где купить натяжные потолки в Москве, то эта фирма является очень привлекательной с точки зрения соотношения цена/качество!
Ремонт станины методом шабрения включает в себя несколько операций.
Преимущества ручного соскоба
Использование ручного соскабливания в производстве станков для повышения уровня точности стало менее распространенным благодаря достижениям в области управления технологическим процессом и повышения жесткости станков. Однако преимущества ручного соскабливания по-прежнему существуют, когда его проводят контролируемым образом.
Однако преимущества ручного соскабливания по-прежнему существуют, когда его проводят контролируемым образом.
Ручной скребок – это процесс использования скребка с ручным или моторным приводом для удаления очень небольшого количества металла с прецизионной поверхности для устранения выступов, оставленных в процессе обработки.Это обеспечивает ровную и точную опорную поверхность, на которую можно устанавливать компоненты машины. За счет увеличения площади контакта подшипника между сопрягаемыми поверхностями повышается жесткость соединения в станке.
Существует около 25 ключевых поверхностей, которые следует очистить на вертикальном обрабатывающем центре, чтобы станок можно было «подогнать» вместе, а не «собрать» для повышения жесткости конструкции. Такие прилегающие поверхности включают, например, компоненты колонны к основанию, картридж шпинделя к корпусу шпинделя, посадочные места блока шарико-винтовой пары к держателю подшипника и рабочий стол к поверхности линейной направляющей тележки. Как только это будет выполнено, конечный пользователь сможет выполнять агрессивные черновые пропилы, за которыми следуют очень тонкие чистовые пропилы, что увеличивает срок службы инструмента и качество поверхности, а также сокращает время цикла.
Как только это будет выполнено, конечный пользователь сможет выполнять агрессивные черновые пропилы, за которыми следуют очень тонкие чистовые пропилы, что увеличивает срок службы инструмента и качество поверхности, а также сокращает время цикла.
 При ручном соскабливании количество контактов на заданной площади двух сопрягаемых компонентов может превышать 50 процентов, с 10 или более точками контакта на квадратный дюйм.Этот улучшенный контакт позволяет передавать механические усилия через структуру в ее наиболее сильные области и помогает предотвратить вибрацию, вызванную частотами ударов резца.
При ручном соскабливании количество контактов на заданной площади двух сопрягаемых компонентов может превышать 50 процентов, с 10 или более точками контакта на квадратный дюйм.Этот улучшенный контакт позволяет передавать механические усилия через структуру в ее наиболее сильные области и помогает предотвратить вибрацию, вызванную частотами ударов резца. Геометрия компонента также улучшена за счет уточнения геометрии станка. Ручное соскабливание у квалифицированных мастеров или мастеров удаляет дефекты поверхности, улучшая геометрию станка. После завершения ручной зачистки выравнивание, включая прямолинейность, значительно улучшается. Это в конечном итоге снижает количество электронной компенсации, требуемой на станке.Например, кронштейны с шарико-винтовой передачей можно выровнять до более узких пределов, улучшая результаты лазерной интерферометрии (метод измерения расстояний с большой точностью) и снижая требуемые уровни электронной компенсации. Прямолинейность оси также можно улучшить, ограничив влияние крена, тангажа и рыскания. А ошибки прямоугольности могут быть уменьшены до нескольких микрон. Все это приводит к повышению объемной точности станка, что помогает конечному пользователю получать детали с более высокой точностью и повышает уверенность в том, что эта точность достижима во всем объеме станка.
А ошибки прямоугольности могут быть уменьшены до нескольких микрон. Все это приводит к повышению объемной точности станка, что помогает конечному пользователю получать детали с более высокой точностью и повышает уверенность в том, что эта точность достижима во всем объеме станка.
Еще один классический пример того, где царапание вручную полезно, – это выравнивание шпинделя по оси Z. В большинстве конструкций машин это достигается за счет наклона шпинделя в отливке головки и зачистки установочной поверхности фланца шпинделя. Поскольку это одна из последних регулировок, сделанных в процессе настройки, это не что-то, что можно обработать в отливке головки, и ее необходимо соскабливать после геометрических проверок.
Станок с улучшенными сопрягаемыми поверхностями основных компонентов обеспечит стабильные результаты в течение более длительного периода времени и потребует меньше переделок.При аккуратных методах соскабливания типичный срок службы более 10 лет не является редкостью и часто может быть легко превышен.
Hardinge Inc.
Китайский производитель конвейеров для стружки, Скребковая цепь, поставщик рабочего освещения
Добро пожаловать на специальную страницу компании Zhongde Machine Tool Accessories Co., Ltd. Мы являемся одним из крупнейших производителей станков в Китае. С момента основания в 2004 году мы имеем 15-летний профессиональный опыт производства.Мы специализируемся на производстве многих видов принадлежностей для станков, основная продукция включает конвейеры для стружки (комбинированный просеивающий конвейер, комбинированный фильтр с двумя фильтрами …
Добро пожаловать на специальную страницу компании Zhongde Machine Tool Accessories Co., Ltd. Мы являемся одним из крупнейших производителей станков в Китае. С момента основания в 2004 году мы имеем 15-летний профессиональный опыт производства. Мы специализируемся на производстве многих видов принадлежностей для станков, основная продукция включает конвейеры для стружки (комбинированный просеивающий конвейер, комбинированный просеивающий конвейер с двумя фильтрами, ленточный конвейер для стружки, прецизионный скребковый конвейер для стружки, винтовой конвейер для стружки и т. Д.), Тросовая цепь (стальная тяговая цепь, стальная алюминиевая цепь, пластиковая тяговая цепь), плоский конвейер (магнитный конвейер), защитные крышки (крышка направляющей, сильфоны, крышки рулонов, крышки фартуков звеньев, доска для крошки блоков, крышки рулонов, органайзер щит, пылезащитная сетка, защитная штора, пылезащитная ткань и т. д.), очиститель рабочего места, рабочий свет (сигнальная лампа, вращающаяся лампа, водонепроницаемая люминесцентная лампа, водонепроницаемая галогенная лампа), экструдированная резина, трубы и фитинги, щетка для механического оборудования, водяные сопла, охлаждающие трубки , Труба для поглощения пыли и так далее.Наша компания создала систему управления качеством и обеспечения качества и прошла сертификацию ISO 9001: 2008. У нас есть современное оборудование, такое как лазерная резка, гибочные станки с ЧПУ и прецизионная сварка, чтобы гарантировать высокое качество продукции. Мы получили высокую репутацию от наших клиентов за высокое качество продукции, конкурентоспособные цены и лучший сервис.
Д.), Тросовая цепь (стальная тяговая цепь, стальная алюминиевая цепь, пластиковая тяговая цепь), плоский конвейер (магнитный конвейер), защитные крышки (крышка направляющей, сильфоны, крышки рулонов, крышки фартуков звеньев, доска для крошки блоков, крышки рулонов, органайзер щит, пылезащитная сетка, защитная штора, пылезащитная ткань и т. д.), очиститель рабочего места, рабочий свет (сигнальная лампа, вращающаяся лампа, водонепроницаемая люминесцентная лампа, водонепроницаемая галогенная лампа), экструдированная резина, трубы и фитинги, щетка для механического оборудования, водяные сопла, охлаждающие трубки , Труба для поглощения пыли и так далее.Наша компания создала систему управления качеством и обеспечения качества и прошла сертификацию ISO 9001: 2008. У нас есть современное оборудование, такое как лазерная резка, гибочные станки с ЧПУ и прецизионная сварка, чтобы гарантировать высокое качество продукции. Мы получили высокую репутацию от наших клиентов за высокое качество продукции, конкурентоспособные цены и лучший сервис. Инновации, честность и ответственность – это наши философские принципы ведения бизнеса, которые мы искренне воплощаем в жизнь. Посвящение нашим усилиям в разработке продуктов, честному реагированию на запросы наших клиентов и ответственности за устойчивое функционирование и управление.Мы всегда стремимся улучшить наши рабочие процессы, усилить контроль качества и улучшить наши возможности, мы также возлагаем на себя большие надежды на создание славы в индустрии принадлежностей для станков с ЧПУ.
Инновации, честность и ответственность – это наши философские принципы ведения бизнеса, которые мы искренне воплощаем в жизнь. Посвящение нашим усилиям в разработке продуктов, честному реагированию на запросы наших клиентов и ответственности за устойчивое функционирование и управление.Мы всегда стремимся улучшить наши рабочие процессы, усилить контроль качества и улучшить наши возможности, мы также возлагаем на себя большие надежды на создание славы в индустрии принадлежностей для станков с ЧПУ.Заказать продукцию можно более или менее, мы торжественно заверяем: сегодня подписание, доставка на следующий день! Бесплатная доставка образцов, может сделать ваш выбор более точным!
Между тем, председатель компании со всеми китайскими и немецкими офицерами посылает вам искреннее приглашение и с нетерпением ждет ваших входящих звонков или писем с обсуждением бизнеса и создания бриллиантов!
Руководство для начинающих по подготовке набора данных с помощью веб-скрейпинга
Эта статья была опубликована как часть Data Science Blogathon
, например базы данных, онлайн-репозитории, API, формы опросов и многие другие. Но когда мы хотим извлечь какие-либо данные с веб-сайта, когда нет средств API, лучшей альтернативой остается веб-скрапинг.
Но когда мы хотим извлечь какие-либо данные с веб-сайта, когда нет средств API, лучшей альтернативой остается веб-скрапинг.
В этой статье вы вкратце узнаете о парсинге веб-сайтов и узнаете, как извлекать данные с веб-сайтов с помощью практической демонстрации с помощью Python. Мы рассмотрим следующие темы.
- Что такое парсинг веб-страниц
- Почему используется парсинг веб-страниц
- Проблемы и руководство по парсингу веб-страниц
- Библиотеки Python для парсинга веб-страниц
- Практический парсинг веб-страниц с помощью Python
- Веб-парсинг с использованием lxml
- Веб-парсинг с использованием Scrapy
- Конечные ноты
Веб-скрапинг – это простой метод, описывающий автоматический сбор огромного количества данных с веб-сайтов.Данные бывают трех типов: структурированные, неструктурированные и частично структурированные. Веб-сайты хранят все типы данных в неструктурированном виде. Веб-парсинг – это метод, который помогает собирать эти данные с веб-сайтов и хранить их в структурированном виде. Сегодня большинство компаний используют веб-парсинг, чтобы принимать правильные бизнес-решения на этом сравнительном рынке. Итак, давайте узнаем, почему и где веб-скрапинг используется чаще всего.
Веб-парсинг – это метод, который помогает собирать эти данные с веб-сайтов и хранить их в структурированном виде. Сегодня большинство компаний используют веб-парсинг, чтобы принимать правильные бизнес-решения на этом сравнительном рынке. Итак, давайте узнаем, почему и где веб-скрапинг используется чаще всего.
Почему используется веб-парсинг?
Мы уже обсуждали, что для автоматического получения данных с веб-сайтов требуется парсинг веб-сайтов, но где он используется. И что для этого нужно? Чтобы лучше понять это, давайте рассмотрим некоторые приложения для парсинга веб-страниц
.- Сравнение цен – Некоторые различные платформы и веб-сайты предоставляют сравнений, плюсов и минусов различных продуктов разных компаний на своих платформах, что позволяет покупателям легко выбрать подходящий продукт.Parsehub – отличный пример, который сравнивает цены на различные товары с разных торговых сайтов. College Dunia – еще один пример, в котором сравниваются рейтинги, структура оплаты курсов разных учебных заведений.

- Исследования и разработки – Большинство веб-сайтов используют файлы cookie, политики конфиденциальности. Они очищают пользовательские данные, такие как временная метка, затраченное время и т. Д., Для проведения различных статистических анализов и лучшего управления отношениями с клиентами.
- Список вакансий – многие порталы вакансий отображают вакансии в разных организациях в зависимости от местоположения, навыков и т. Д.Они собирают данные со страницы вакансий организации, чтобы перечислить множество вакансий в разных компаниях на одной платформе.
- Сбор электронной почты – компаний, которые используют электронную почту в маркетинговых целях, используют парсинг веб-страниц для сбора большого количества электронных писем с разных веб-сайтов и рассылки массовых электронных писем.

Теперь я надеюсь, что это дает четкое понимание того, почему веб-скрапинг необходим и используется чаще всего, и это приложение расширяет ваши представления, и вы можете подумать о многих различных приложениях, которые он используется в настоящее время.
Проблемы и руководство по очистке
Если вы знакомы с HTML и CSS, тогда очень легко понять и легко выполнить парсинг веб-страниц, потому что в двух словах, путем очистки веб-сайтов мы извлекаем данные веб-сайтов, которые возвращаются в форме документа HTML, а CSS предназначен для получения конкретных данных, которые мы ищем. . И это также важно, потому что удаление веб-страниц представляет собой небольшую проблему.
- Разнообразие – Каждый веб-сайт индивидуален, имеет разное форматирование, разные шаблоны.Вам необходимо просмотреть HTML-код веб-сайта, чтобы извлечь соответствующую информацию.
- Долговечность – Сайты обновляются со временем. новые публикации и форматирование постоянно меняются, поэтому после того, как вы создали веб-парсер, и он работает безупречно, это не означает, что всегда через некоторое время он будет работать нормально.
Но в этой статье мы будем работать с уровня земли, чтобы вы могли легко следить за ней.
запросов – Это самая простая библиотека для парсинга веб-страниц.Запрос представляет собой встроенный модуль python, который позволяет отправлять HTTP-запросы, такие как GET, POST, и т. Д., На веб-сайты, использующие python. Получение HTML-содержимого веб-страницы – это первый и самый важный шаг при сканировании веб-страниц. Благодаря простоте использования, он стал девизом HTTP для людей. Однако запросы не анализируют полученное содержимое HTML. для этого нам потребуются другие библиотеки.
Beautiful Soup (bs4) – Beautiful Soup – это библиотека Python, используемая для парсинга веб-страниц.Он находится в верхней части парсера HTML или XML, который предоставляет идиомы Python для итерации, поиска и изменения дерева синтаксического анализа. Он автоматически конвертирует входящие документы в Unicode, а исходящие – в UTF-8. Beautiful Soup прост в освоении, надежен, удобен для начинающих и является наиболее часто используемой библиотекой для парсинга веб-страниц в последнее время с запросом.
lxml – Это высокопроизводительная, быстрая библиотека для анализа HTML и XML. Это быстрее красивого супа. Это хорошо работает, когда мы стремимся очистить большие наборы данных.Он также позволяет извлекать данные из HTML с помощью селекторов XPath и CSS.
pip install lxml
Scrapy – Scrapy – это не просто библиотека, это полноценный фреймворк для парсинга веб-страниц. Scrapy помогает эффективно и эффективно очищать большой объем набора данных. Его можно использовать для самых разных целей, от интеллектуального анализа данных до мониторинга и автоматического тестирования. Scrapy создает пауков, которые ползают по веб-сайтам и извлекают данные. Лучшее в scrapy – это асинхронность, и с помощью spacy вы можете одновременно выполнять несколько HTTP-запросов.Вы также можете создать конвейер с помощью scrapy.
pip install scrapyПрактический парсинг веб-страниц с помощью Python
Описание проблемы
Мы собираемся очистить данные с веб-сайта Ambition Box. Ambition Box – это платформа, на которой перечислены вакансии в различных компаниях Индии. Если вы посетите страницу компаний, вы можете увидеть название компании, рейтинг, обзор, сколько лет компании и другую информацию о ней. Поэтому мы стремимся получить эти данные в виде таблицы, которая состоит из названия компании, рейтинга, обзора, возраста компании, количества сотрудников и т. Д.Есть около 33 страниц, и на каждой странице указано около 30 компаний, и мы хотим получить все 33 страницы данных каждой компании в фреймворке данных.
Ambition Box – это платформа, на которой перечислены вакансии в различных компаниях Индии. Если вы посетите страницу компаний, вы можете увидеть название компании, рейтинг, обзор, сколько лет компании и другую информацию о ней. Поэтому мы стремимся получить эти данные в виде таблицы, которая состоит из названия компании, рейтинга, обзора, возраста компании, количества сотрудников и т. Д.Есть около 33 страниц, и на каждой странице указано около 30 компаний, и мы хотим получить все 33 страницы данных каждой компании в фреймворке данных.
Приступим!
Импортировать библиотекиимпортировать панд как pd запросы на импорт из bs4 импорт BeautifulSoup импортировать numpy как np
Оформить заявку
Теперь мы создадим HTTP-запрос к веб-сайту Ambition Box, и он предоставит нам ответное содержимое HTML-документа.
webpage = requests.get ('https://www.ambitionbox.com/list-of-companies?page=1') .text
Разобрать ответ, используя красивый суп У нас есть HTML-контент, и для извлечения данных, присутствующих в нем, мы будем использовать красивый суп, который создает вокруг него синтаксический анализатор. Если вы распечатываете вывод парсера с помощью функции prettify, вы можете увидеть извлеченный документ в удобочитаемом формате.
Если вы распечатываете вывод парсера с помощью функции prettify, вы можете увидеть извлеченный документ в удобочитаемом формате.
Как мы найдем каждый нужный нам текст?
Чтобы получить любое имя из HTML-документа, существует специальный тег, в котором оно записывается.Если вы зайдете на веб-сайт и щелкните правой кнопкой мыши, если вы перейдете в раздел проверки, вы увидите, что информация о каждой компании находится в отдельном теге подразделения (div). В этом есть уникальный класс или идентификатор для элемента, поэтому, используя тег, класс, идентификатор, мы можем получить желаемые результаты. заголовок пишется в теге h2. например, если мы хотим получить к нему доступ, это просто.
soup.find_all ('h2') [0] .text Как получить название компании? Названия всех компаний записаны в теге h3.мы можем запустить цикл и получить все названия компаний на первой странице. когда мы пишем find all, он извлекает объект списка, и в этом случае мы получаем доступ к индексу с отсчетом от нуля, который является заголовком текста, и получаем доступ к тексту, написанному в нем. Функция полосы используется, чтобы избежать лишних пробелов, которые используются на веб-странице для дизайна.
Функция полосы используется, чтобы избежать лишних пробелов, которые используются на веб-странице для дизайна.
Если вы проводите проверку по рейтингу, обзору компаний, то все они записываются в теге абзаца (p). Наряду с тегом абзаца у них есть уникальное имя класса, по которому мы можем их идентифицировать.У рейтинга есть класс рейтинга, у отзывов есть класс обзора. Но тип компании, возраст компании, местонахождение штаб-квартиры и несколько сотрудников находятся в одном теге и имеют одно и то же имя класса. Для доступа к этому мы будем использовать индексирование списка.
для i в soup.find_all ('p'):
печать (i.text.strip ())
Создание списка каждой функции Теперь, как мы видели, мы будем обращаться к каждой функции с помощью тега и класса. поэтому давайте создадим отдельный список для каждого объекта, длина которого будет 30.Во-первых, мы сохраним список всех 30 подразделений, означающих все подразделения компании, в переменной и применим к нему цикл.
компания = soup.find_all ('div', class _ = 'company-content-wrapper')
print (len (компания)) # 30 Теперь мы можем легко перебрать переменные компании и получить всю информацию на первой странице.
name = []
рейтинг = []
reviews = []
comp_type = []
head_q = []
how_old = []
no_of_employees = []
для компа в компании:
имя.добавить (comp.find ('h3'). text.strip ())
rating.append (comp.find ('p', class_ = "rating"). text.strip ())
reviews.append (comp.find ('a', class_ = "review-count"). text.strip ())
comp_type.append (comp.find_all ('p', class_ = 'infoEntity') [0] .text.strip ())
head_q.append (comp.find_all ('p', class _ = 'infoEntity') [1] .text.strip ())
how_old.append (comp.find_all ('p', class _ = 'infoEntity') [2] .text.strip ())
no_of_employees.append (comp.find_all ('p', class _ = 'infoEntity') [3] .text.strip ())
# создание фрейма данных для всего списка
features = {'name': name, 'rating': рейтинг, 'reviews': отзывы,
'company_type': comp_type, 'Head_Quarters': head_q, 'Company_Age': how_old,
'No_of_Employee': no_of_employees}
df = pd. DataFrame (функции)  DataFrame (функции)
DataFrame (функции) Выше приведен полный фрейм данных только для первой страницы, а теперь давайте подбросим наш энтузиазм и получим данные для всех страниц.
Создание окончательного фрейма данныхДавайте подготовим набор данных с помощью веб-скрейпинга!
Теперь вы лучше понимаете парсинг веб-страниц и то, как данные поступают в отдельную функцию. Итак, мы готовы создать окончательный фрейм данных всех 33 страниц, и каждая страница содержит данные 30 компаний. Но на некоторых страницах есть некоторые несоответствия, например, небольшая информация о компании не предоставляется, поэтому нам нужно с этим справиться.поэтому мы поместим каждую функцию в блок try-except, и если данные отсутствуют, мы добавим значение Null вместо него. Для получения данных с каждой страницы мы должны делать запрос снова и снова на другой странице в цикле и извлекать его данные, и после этого все происходит так же, как указано выше.
финал = pd.DataFrame () для j в диапазоне (1, 33): # отправить запрос на конкретную страницу webpage = requests.
 get ('https://www.ambitionbox.com/list-of-companies?page= {}' .format (j)).текст
soup = BeautifulSoup (веб-страница, 'lxml')
компания = soup.find_all ('div', class_ = 'company-content-wrapper')
name = []
рейтинг = []
reviews = []
comp_type = []
head_q = []
how_old = []
no_of_employees = []
для компа в компании:
пытаться:
name.append (comp.find ('h3'). text.strip ())
Кроме:
имя.аппенд (нп.нан)
пытаться:
rating.append (comp.find ('p', class_ = "rating"). text.strip ())
Кроме:
рейтинг.добавить (np.nan)
пытаться:
reviews.append (comp.find ('a', class_ = "review-count"). text.strip ())
Кроме:
reviews.append (np.nan)
пытаться:
comp_type.append (comp.find_all ('p', class_ = 'infoEntity') [0] .text.strip ())
Кроме:
comp_type.append (np.nan)
пытаться:
head_q.append (comp.find_all ('p', class _ = 'infoEntity') [1] .text.strip ())
Кроме:
head_q.append (np.
get ('https://www.ambitionbox.com/list-of-companies?page= {}' .format (j)).текст
soup = BeautifulSoup (веб-страница, 'lxml')
компания = soup.find_all ('div', class_ = 'company-content-wrapper')
name = []
рейтинг = []
reviews = []
comp_type = []
head_q = []
how_old = []
no_of_employees = []
для компа в компании:
пытаться:
name.append (comp.find ('h3'). text.strip ())
Кроме:
имя.аппенд (нп.нан)
пытаться:
rating.append (comp.find ('p', class_ = "rating"). text.strip ())
Кроме:
рейтинг.добавить (np.nan)
пытаться:
reviews.append (comp.find ('a', class_ = "review-count"). text.strip ())
Кроме:
reviews.append (np.nan)
пытаться:
comp_type.append (comp.find_all ('p', class_ = 'infoEntity') [0] .text.strip ())
Кроме:
comp_type.append (np.nan)
пытаться:
head_q.append (comp.find_all ('p', class _ = 'infoEntity') [1] .text.strip ())
Кроме:
head_q.append (np. nan)
пытаться:
how_old.append (сост.find_all ('p', класс _ = 'infoEntity') [2] .text.strip ())
Кроме:
how_old.append (np.nan)
пытаться:
no_of_employees.append (comp.find_all ('p', class _ = 'infoEntity') [3] .text.strip ())
Кроме:
no_of_employees.append (np.nan)
# создание фрейма данных для всего списка
features = {'name': name, 'rating': рейтинг, 'reviews': отзывы,
'company_type': comp_type, 'Head_Quarters': head_q, 'Company_Age': how_old,
'No_of_Employee': no_of_employees}
df = pd.DataFrame (функции)
final = final.append (df, ignore_index = True)
nan)
пытаться:
how_old.append (сост.find_all ('p', класс _ = 'infoEntity') [2] .text.strip ())
Кроме:
how_old.append (np.nan)
пытаться:
no_of_employees.append (comp.find_all ('p', class _ = 'infoEntity') [3] .text.strip ())
Кроме:
no_of_employees.append (np.nan)
# создание фрейма данных для всего списка
features = {'name': name, 'rating': рейтинг, 'reviews': отзывы,
'company_type': comp_type, 'Head_Quarters': head_q, 'Company_Age': how_old,
'No_of_Employee': no_of_employees}
df = pd.DataFrame (функции)
final = final.append (df, ignore_index = True) Мы создали динамический URL-адрес каждой страницы, чтобы сделать запрос и получить данные, и вы можете посмотреть на окончательный фрейм данных. Вот так и делается парсинг веб-страниц.
Веб-парсинг с использованием lxmlТеперь у нас есть понимание того, как работает парсинг веб-страниц, и как извлечь единичный фрагмент информации с веб-сайта и реализовать фреймворк данных. Что, если мы хотим извлечь некоторые абзацы или какую-то информативную строку из какого-либо блога или статьи, тогда это легко сделать с lxml, используя XPath.
Мы извлечем абзац из одной из статей Analytics Vidhya, используя lxml, всего с несколькими строками кода. Я надеюсь, что вы уже установили lxml с помощью команды pip и готовы выполнить следующие шаги.
Шаг-1) Проверьте абзац, который необходимо утилизироватьПосетите статью, выберите любой абзац, щелкните его правой кнопкой мыши и выберите параметр проверки.
Шаг 2) Щелкните правой кнопкой мыши элемент исходного кода справа
Когда вы щелкнете по Inspect, откроется раздел, в котором щелкните правой кнопкой мыши выбранный элемент и скопируйте XPath элемента, перейдите в среду кодирования и сохраните путь в переменной в виде строки.
Шаг 3) HTTP-запрос на получение содержимого HTML
Сделайте HTTP-запросы на веб-сайте статьи для получения содержимого HTML.
запросов на импорт из lxml import html URL = 'https://www.analyticsvidhya.com/blog/2021/09/a-comprehensive-guide-on-neural-networks-performance-optimization/' путь = '// * [@ id = "1"] / p [5]' response = requests.get (URL)Шаг 4) Получить байтовую строку и отфильтровать исходный код
с помощью парсера lxml анализирует содержимое ответа, полученное по запросу, и преобразует его в объект исходного кода.
byte_data = response.content исходный_код = html.fromstring (byte_data)Шаг 5) Перейти к предпочтительному элементу HTML
Теперь, используя Xpath, извлекаем желаемый абзац, который мы стремимся получить.
tree = source_code.xpath (путь) print (дерево [0] .text_content ())
Это сделано, и это просто – использование парсера lxml для извлечения большого количества данных с веб-сайта в нашей среде кодирования.
Практический парсинг веб-страниц с использованием ScrapyЭффективный парсинг данных за несколько минут – это цель каждого, которую выполняет scrapy.с несколькими ботами-пауками, которые сканируют веб-сайт, чтобы получить данные для вас. В этом разделе мы будем использовать scrapy в нашем локальном блокноте jupyter (коллаборация Goole) и очищать данные в нашем фреймворке данных. Scrapy предоставляет веб-сайт с расценками по умолчанию для изучения веб-скрейпинга с помощью scrapy.
Он состоит из различных цитат, а также имени автора и тегов, которым он принадлежит. мы создадим фрейм данных с 3 столбцами: цитата, автор и тег. После установки spacy выполните следующие действия. После извлечения деталей с веб-сайта мы запишем детали в файл JSON и загрузим фрейм данных из JSON с помощью библиотеки Pandas.
Step-1) set Интерактивная оболочка pythonиз IPython.core.interactiveshell импорт InteractiveShell импортный лом из scrapy.crawler import CrawlerProcessШаг 2) Настройка трубопровода
здесь мы создаем класс, который создает новый файл JSON и функцию для записи всех элементов, обнаруженных во время парсинга, в файл JSON, где каждая строка содержит один элемент JSON.
#setup pipeline
импортировать json
класс JsonWriterPipeline (объект):
def open_spider (сам, паук):
себя.файл = открытый ('quoteresult.jl', 'ш')
def close_spider (я, паук):
self.file.close ()
def process_item (я, предмет, паук):
line = json.dumps (dict (элемент)) + «n»
self.file.write (строка)
вернуть товар шаг-3) Определите паук Теперь нам нужно определить нашего поискового робота (Spider), и мы передаем URL-адрес, откуда следует начать синтаксический анализ и какие значения нужно получить. Я установил уровень ведения журнала на предупреждение, чтобы ноутбук не был перегружен.
#define spider
импорт журнала
класс QuotesSpider (scrapy.Spider):
name = "котировки"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
custom_settings = {
'LOG_LEVEL': ведение журнала.ПРЕДУПРЕЖДЕНИЕ,
'ITEM_PIPELINES': {'__main __. JsonWriterPipeline': 1}, # Используется для конвейера 1
'FEED_FORMAT': 'json', # Используется для конвейера 2
'FEED_URI': 'quoteresult.json '# Используется для конвейера 2
}
def parse (self, response):
для цитаты в response.css ('div.quote'):
урожай {
'текст': quote.css ('span.text :: text'). extract_first (),
'автор': quote.css ('span small :: text'). extract_first (),
'теги': quote.css ('div.tags a.tag :: text'). extract (),
} Каждая цитата записывается в отдельный тег деления с именем класса в качестве цитаты, поэтому мы извлекли все цитаты с помощью этого селектора CSS разделения и цитаты.
Шаг 4) Запустите гусеничный ходопределяют процесс сканирования scrapy и передают класс паука, чтобы начать извлечение данных.
#start crawler
process = CrawlerProcess ({
'USER_AGENT': 'Mozilla / 4.0 (совместимый; MSIE 7.0; Windows NT 5.1)'
})
process.crawl (QuotesSpider)
process.start ()
Шаг 5) Создание фреймов данных Полученные данные сохраняются в файле JSON, и мы загрузим их как фрейм данных с помощью pandas.
импортировать панд как pd
dfjson = pd.read_json ('quoteresult.json') Вот как работает scrapy, который помогает вам очень быстро извлекать большой объем данных с веб-сайтов.
Конечные примечанияВ этой статье мы узнали о парсинге веб-страниц, его приложениях и о том, почему он используется повсеместно. Мы выполнили практический веб-скрапинг с веб-сайтов, чтобы получить информацию о различных компаниях и подготовить фреймворк, который используется для дальнейших целей проекта машинного обучения с использованием красивого супа.Мы также узнали о библиотеке lxml и провели практическую демонстрацию. Кроме того, мы узнали о боссе scrapy имени библиотеки парсинга веб-страниц и о том, почему это так известно.
Вы можете сделать гораздо больше, чтобы превратить его в конечный проект. Например, когда мы получаем информацию о конкретной компании, затем пытаемся найти компанию в Google и получить информацию о ее генеральном директоре, контактном номере, услугах и т. Д., И это будет очень интересно сделать.
Надеюсь, вам понравилась статья, и на каждом этапе ее было легко отслеживать.Если у вас есть какие-либо сомнения или отзывы, опубликуйте их в разделе комментариев ниже.
Об автореЯ учусь на степень бакалавра компьютерных наук. Я энтузиаст науки о данных и люблю учиться, работать в области технологий данных.
Свяжитесь со мной в Linkedin
Ознакомьтесь с другими моими статьями здесь и в Blogspot
Спасибо, что уделили время!
Носители, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению автора.
СвязанныеПолное руководство по веб-парсингу для всех
В этом посте мы узнаем, как использовать инструменты веб-парсинга и API-интерфейсы для быстрого и эффективного парсинга для одностраничных приложений. Это может помочь нам собрать и использовать ценные данные, которые не всегда доступны через API. Давайте нырнем.
Веб-скрапинг – это метод, используемый для извлечения данных с веб-сайтов с помощью определенных инструментов или API.Мы извлекаем данные либо для коммерческих целей, либо для анализа данных. Здесь мы сосредоточимся на инструментах, которые могут использоваться как разработчиками, так и не разработчиками.
Мы выполняем парсинг веб-страниц, потому что целевой веб-сайт не предоставил свой API. Вот несколько распространенных сценариев веб-парсинга:
- Сбор данных о товарах с веб-сайтов электронной коммерции.
- Скрипинг сайтов бронирования отелей для сбора отзывов, оценок и цен на отель.
- Скребок писем для таргетинга на клиентов.
- Очистка финансовых веб-сайтов для анализа данных или подготовки модели машинного обучения.
Начать парсинг веб-страниц очень просто, он разделен на две простые части –
- Использование инструмента для очистки веб-страниц для выполнения HTTP-запроса на извлечение данных.
- Извлечение важных данных JSON путем анализа очищенных данных HTML.
Теперь, после успешной регистрации, вы будете перенаправлены на панель инструментов, которая выглядит как ниже
. Теперь, если вы разработчик и не хотите использовать этот инструмент, просто перейдите к их документации по API и запустите парсинг.Сначала позвольте мне просто объяснить, что здесь означает каждое 8 полей ввода.
- Вы должны вставить URL-адрес веб-сайта, который вы собираетесь очистить.
- Вставьте ключ своей учетной записи, который доступен прямо над этим инструментом.
- Теперь вы можете визуализировать JavaScript или оставить все как есть. Визуализация JavaScript означает, что он откроет этот веб-сайт в Chrome без заголовков и извлечет все динамические данные, доступные на этом целевом веб-сайте.Если вы думаете, что цель веб-сайт статичен, оставьте его как есть.
- Тогда у вас есть опция прокси премиум-класса, которая позволяет использовать прокси премиум-класса для веб-сайтов, которые труднее очистить.
- Тогда у вас есть прокси-сервер географического положения, который поможет вам получить локальные данные любой страны.
- Последние три параметра предназначены для указания атрибутов и тегов HTML, с помощью которых Scrapingdog предоставляет нам данные JSON непосредственно из очищенных данных HTML.
Затем просто нажмите Очистить и вуаля.Ваши данные HTML будут доступны в другом поле. Разве это не потрясающе? Как быстро мы можем собирать данные сегодня. Итак, всего за 2 секунды без какой-либо настройки вам удалось очистить динамический веб-сайт. Вы также можете напрямую скопировать эти данные с помощью кнопки «Копировать данные».
Данные, извлеченные из Scrapingdog Мы получаем похожий HTML-контент, который мы получаем при запросе из Chrome или любого браузера.Теперь нам нужна помощь Chrome Developer Tools для поиска через HTML-код веб-страницы и выберите необходимые данные. Вы можете узнать больше о Chrome DevTools здесь.Мы хотим очистить заголовок новостей в формате JSON. Вы можете просмотреть HTML-код веб-страницы, щелкнув правой кнопкой мыши в любом месте веб-страницы и выбрав «Проверить».
Инструменты разработчика Chrome для проверки HTMLА теперь еще одна замечательная особенность Scrapingdog.com. Мы можем указать атрибуты и теги, чтобы получить ответ JSON со всем заголовком новостей. Теперь атрибут – «класс», его имя – «заголовок», а тег – «td». Просто укажите эту информацию внутри инструмента. Как показано ниже.
Затем снова просто нажмите Очистить, чтобы получить данные JSON. Вы получите что-то вроде того, что показано ниже.
JSON получен от ScrapingdogФантастика! Это то, что мы искали. Это ответ в формате JSON, который содержит все заголовки новостей на ycombinator.com. Это самый быстрый способ очистки любого веб-сайта. Вы можете просто скопировать и поделиться им с кем угодно или, возможно, использовать в своем проект.Все это также можно сделать с помощью их API. Таким образом, мы можем извлекать данные из большого количества различных веб-сайтов, включая Google, Facebook, Instagram и т. Д. Таким образом, наша еда приготовлена и выглядит восхитительно.
Ой! он также предлагает расширение, которое можно использовать удаленно, если вы не хотите получать доступ к панели управления.В этой статье мы впервые поняли, что такое парсинг веб-страниц и как его можно использовать для автоматизации различных операций по сбору данных с различных веб-сайтов.
Многие веб-сайты используют архитектуру одностраничных приложений (SPA) для динамической генерации контента на своих веб-сайтах с помощью JavaScript. Итак, в нашем следующем уроке мы узнаем, как очистить динамические веб-сайты, не будучи заблокированными. На следующей неделе я выпущу второй урок с гораздо большим количеством приключений. Так что оставайтесь с нами.
Не стесняйтесь комментировать и спрашивать меня о чем угодно. Вы можете подписаться на нас в Twitter и на Medium.Спасибо за прочтение! 👍Машинное обучение и парсинг веб-страниц
Если вы в последнее время читали новости, возможно, вы сошли с ума от последних изобретений в области машинного обучения, таких как интеллектуальные смартфоны на рынке, а также беспилотные автомобили, которые вот-вот появятся на улицах в любом году. теперь и береги дороги без происшествий; Позвольте мне сказать вам, что даже ваш бизнес может извлечь выгоду из простого машинного интеллекта.
Машинное обучение и парсинг веб-страниц
Многие компании уже довольно давно используют веб-парсеры. В то время как раньше веб-скрейпинг означал, что десять стажеров сидят и находят данные по нужной вам теме, или информацию о конкурентах, или даже информацию о продукте, чтобы заполнить таблицы Excel, сегодня вы можете подписаться на сервисы веб-скрапинга, которые будут использовать ботов для получения этих данных. выполняется без какого-либо ручного вмешательства, что ускоряет работу и повышает надежность и точность данных.
Если вы говорите об искусственном интеллекте, есть некоторая разница между машинным обучением и искусственным интеллектом. В машинном обучении пользователь должен научить машину, что правильно, а что нет, то есть вы даете ей набор правил и предоставляете ей набор обучающих примеров. Этот тренировочный процесс важен для достижения большей точности в выполняемой задаче. Чем больше он обучен, тем больше качество данных будет определять его производительность на более позднем этапе.В случае искусственного интеллекта, или, как вы могли бы назвать его, обучения без учителя, обучение осуществляется само по себе, со слабо связанными правилами и небольшой подготовкой. Он может создавать свой собственный путь при движении. Чем больше используется, тем больше он учится и может лучше работать. Это стало возможным благодаря использованию искусственных нейронных сетей и глубокого обучения, обычно используемых для распознавания речи и объектов, анализа тональности, сегментации изображений, обработки естественного языка, а также распознавания и имитации движения человека.
Интернет – это крупнейшее хранилище данных, как обширных, так и обширных. Огромные возможности, которые дает такой невероятный объем данных, невообразимы с ручкой и бумагой. Однако сама проблема заключается в навигации по этим необработанным данным для получения некоторой значимой и разумной информации. Требуется некоторое время и усилия, чтобы сканировать данные из Интернета, даже несмотря на то, что технологии веб-скрапинга ушли далеко за пределы своих первых дней. Однако ситуация меняется, и такие лаборатории, как лаборатория Массачусетского технологического института, работают над интеллектуальными системами, которые могут собирать информацию из нескольких источников в Интернете и даже учиться делать это самостоятельно.
Извлечение структурированных данных из неструктурированных документов может выполняться автоматически с использованием таких изученных методов. Проще говоря, в этих исследованиях говорится о системах, которые будут думать так же, как и человек, глядя на некоторые документы. Когда мы не можем найти какую-либо информацию, чтобы заполнить недостающий пробел в документе, мы пытаемся заполнить его альтернативной информацией. Алгоритм делает то же самое и сохраняет эту недавно обнаруженную информацию в своем репозитории.
Системы извлечения данных на основе искусственного интеллекта включают так называемый «показатель достоверности».Эта оценка определяет вероятность классификации, которая выполняется машиной, будучи статистически правильной, и выводится из данных, на которых она была обучена до этого момента. Если рассчитанная оценка достоверности не соответствует пороговому значению, заданному пользователем, система сама выполнит поиск в Интернете и получит более релевантные данные. После того, как показатель достоверности будет достигнут, произойдет интеграция новых данных с исходным документом, и он будет представлен вам. Это циклический процесс, в котором машина пытается создать целый банк данных, который вам нужен, отбирая кусочки и кусочки оттуда и там, а затем вычисляя оценку достоверности и возвращаясь к ней, если один дамп данных не удается. достичь порогового значения.
Этот механизм обучения известен как «обучение с подкреплением» и вознаграждает себя при правильном обнаружении. То есть, как только он находит некоторые данные, которые являются удовлетворительными и превышают пороговую оценку, он не только предоставляет их пользователю, но также сохраняет всю связанную информацию, чтобы в следующий раз, когда он выполняет аналогичную задачу, он уже знает и знает пути, которые ему предстоит пройти. Машина пытается объединить данные из разных источников, не влияя на общую точность и сохраняя конечный результат как можно ближе к требуемому порогу.
Чтобы проверить, насколько хорошо такая система искусственного интеллекта может извлекать данные, исследователи из Массачусетского технологического института дали ей образец тестового задания. Аппарат должен был проанализировать сеть, посвященную массовым расстрелам в Соединенных Штатах, и каким-то образом собрать имя стрелка, а также другие детали, такие как количество раненых, погибших и местонахождение. Система смогла получить точные данные, опередив традиционные механизмы очистки данных более чем на десять процентов.
В связи с постоянно возрастающей потребностью в данных и их извлечении, а также с хорошо известными проблемами, связанными с их получением, искусственный интеллект или машинное обучение могут быть тем, чего не хватает во всем уравнении.Исследования в этой области, хотя и находятся на ранней стадии, довольно многообещающие и дают нам представление о будущем, в котором интеллектуальные боты со способностями человека смогут сканировать Интернет и получать желаемую информацию.
Это может изменить правила игры в исследовательских задачах, когда многие люди выполняют ручную работу для сбора важных данных, которые нелегко найти, или для решения бизнес-задач с данными, с которыми традиционные инструменты для парсинга не могут справиться. Новые исследования в этой области и компании, поощряющие все больше и больше веб-скрапинга и обработки данных, помогут поставщикам услуг вкладывать больше средств в интеллектуальные поисковые роботы, и, возможно, эти службы скоро станут лучшими друзьями исследователей и компаний.Так что, может быть, вам действительно не нужен терминатор, чтобы работать на вас. просто интеллектуальный поисковый робот.
Веб-парсинг с помощью Python – Руководство для начинающих
Веб-парсинг с помощью Python
Представьте, что вам нужно извлечь большой объем данных с веб-сайтов, и вы хотите сделать это как можно быстрее. Как бы вы это сделали, не заходя на каждый веб-сайт вручную и не получая данных? Что ж, ответ на этот вопрос – «Веб-скрапинг». Веб-парсинг просто упрощает и ускоряет эту работу.
В этой статье о веб-парсинге с помощью Python вы вкратце узнаете о парсинге веб-сайтов и узнаете, как извлекать данные с веб-сайта с помощью демонстрации. Я расскажу о следующих темах:
Почему используется веб-скрапинг?Веб-парсинг используется для сбора больших объемов информации с веб-сайтов. Но зачем кому-то собирать такие большие данные с веб-сайтов? Чтобы узнать об этом, давайте рассмотрим приложения веб-скрапинга:
- Сравнение цен: Такие службы, как ParseHub, используют веб-скрапинг для сбора данных с веб-сайтов онлайн-покупок и использования их для сравнения цен на товары.
- Сбор адресов электронной почты: Многие компании, использующие электронную почту в качестве средства маркетинга, используют парсинг веб-страниц для сбора идентификаторов электронной почты, а затем рассылают массовые электронные письма.
- Парсинг социальных сетей: Парсинг веб-страниц используется для сбора данных с веб-сайтов социальных сетей, таких как Twitter, для выявления тенденций.
- Исследования и разработки: Веб-скрапинг используется для сбора большого набора данных (статистика, общая информация, температура и т. Д.) С веб-сайтов, которые анализируются и используются для проведения опросов или для исследований и разработок.
- Объявления о вакансиях: Подробная информация о вакансиях и собеседованиях собирается с разных веб-сайтов, а затем перечисляется в одном месте, чтобы пользователь мог легко получить к ней доступ.
Веб-скрапинг – это автоматизированный метод, используемый для извлечения больших объемов данных с веб-сайтов. Данные на сайтах неструктурированы. Веб-парсинг помогает собирать эти неструктурированные данные и хранить их в структурированной форме. Есть разные способы очистки веб-сайтов, таких как онлайн-сервисы, API-интерфейсы или написания собственного кода.В этой статье мы увидим, как реализовать парсинг веб-страниц с помощью Python.
Законен ли парсинг веб-страниц?Говоря о том, является ли веб-скрапинг законным или нет, некоторые веб-сайты разрешают очистку веб-страниц, а некоторые – нет. Чтобы узнать, разрешено ли веб-сканирование на веб-сайте или нет, вы можете посмотреть файл robots.txt на веб-сайте. Вы можете найти этот файл, добавив «/robots.txt» к URL-адресу, который вы хотите очистить. В этом примере я просматриваю веб-сайт Flipkart. Итак, чтобы увидеть «robots.txt »по адресу www.flipkart.com/robots.txt.
Получите глубокие знания о Python и его разнообразных приложениях. Узнайте больше! Почему Python хорош для парсинга веб-страниц?Вот список функций Python, которые делают его более подходящим для парсинга веб-страниц.
- Простота использования: Python прост в кодировании. Вам не нужно добавлять точки с запятой «;» или фигурные скобки «{}» в любом месте. Это делает его менее беспорядочным и простым в использовании.
- Большая коллекция библиотек: Python имеет огромную коллекцию библиотек, таких как Numpy, Matlplotlib, Pandas и т. Д., который предоставляет методы и услуги для различных целей. Следовательно, он подходит для парсинга веб-страниц и для дальнейшего манипулирования извлеченными данными.
- Динамически типизированный: В Python вам не нужно определять типы данных для переменных, вы можете напрямую использовать переменные везде, где это необходимо. Это экономит время и ускоряет вашу работу.
- Легко понятный синтаксис: Синтаксис Python легко понять, главным образом потому, что чтение кода Python очень похоже на чтение оператора на английском языке.Он выразительный и легко читаемый, а отступы, используемые в Python, также помогают пользователю различать различные области / блоки в коде.
- Маленький код, большая задача: Для экономии времени используется парсинг веб-страниц. Но что толку, если вы тратите больше времени на написание кода? Что ж, не обязательно. В Python вы можете писать небольшие коды для выполнения больших задач. Таким образом, вы экономите время даже при написании кода.
- Сообщество: Что делать, если вы застряли при написании кода? Тебе не о чем беспокоиться.Сообщество Python имеет одно из самых больших и активных сообществ, к которому вы можете обратиться за помощью.
Когда вы запускаете код для очистки веб-страниц, на указанный вами URL-адрес отправляется запрос. В ответ на запрос сервер отправляет данные и позволяет вам читать HTML- или XML-страницу. Затем код анализирует страницу HTML или XML, находит данные и извлекает их.
Чтобы извлечь данные с помощью парсинга веб-страниц с помощью Python, вам необходимо выполнить следующие основные шаги:
- Найдите URL-адрес, который вы хотите очистить
- Проверка страницы
- Найдите данные, которые вы хотите извлечь
- Напишите код
- Запустите код и извлеките данные.
- Сохраните данные в нужном формате.
. Теперь давайте посмотрим, как извлечь данные с веб-сайта Flipkart с помощью Python.
Изучите Python, глубокое обучение, НЛП, искусственный интеллект, машинное обучение с помощью этих курсов AI и ML. Программа сертификации диплома PG от NIT Warangal.
Библиотеки, используемые для парсинга веб-страницКак мы знаем, Python имеет различные приложения и разные библиотеки для разных целей. В нашей дальнейшей демонстрации мы будем использовать следующие библиотеки:
- Selenium : Selenium – это библиотека для веб-тестирования.Он используется для автоматизации действий браузера.
- BeautifulSoup : Beautiful Soup – это пакет Python для анализа документов HTML и XML. Он создает деревья синтаксического анализа, которые помогают легко извлекать данные.
- Pandas : Pandas – это библиотека, используемая для обработки и анализа данных. Он используется для извлечения данных и сохранения их в желаемом формате.
Подпишитесь на наш канал YouTube, чтобы получать новости ..!
Пример парсинга веб-сайтов: парсинг веб-сайта FlipkartПредварительные требования:
- Python 2.x или Python 3.x с Selenium , BeautifulSoup, pandas установленных библиотек
- Браузер Google Chrome
- Операционная система Ubuntu
Давайте приступим!
Шаг 1. Найдите URL-адрес, который вы хотите очистить.В этом примере мы собираемся очистить веб-сайт Flipkart , чтобы извлечь цену, имя и рейтинг ноутбуков. URL-адрес этой страницы: https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2.
Шаг 2: Проверка страницы
Данные обычно вкладываются в теги. Итак, мы проверяем страницу, чтобы увидеть, в какой тег вложены данные, которые мы хотим очистить. Чтобы проверить страницу, просто щелкните элемент правой кнопкой мыши и выберите «Проверить».
Когда вы щелкнете по вкладке «Inspect», вы увидите, что открыто «Browser Inspector Box».
Шаг 3: Найдите данные, которые вы хотите извлечьДавайте извлечем цену, имя и рейтинг, которые находятся в теге «div» соответственно.
Шаг 4. Напишите кодСначала давайте создадим файл Python. Для этого откройте терминал в Ubuntu и введите gedit <имя вашего файла> с расширением .py.
Я назову свой файл «web-s». Вот команда:
gedit web-s.py
Теперь давайте запишем наш код в этот файл.
Сначала импортируем все необходимые библиотеки:
из selenium import webdriver из BeautifulSoup импортировать BeautifulSoup import pandas as pd
Чтобы настроить webdriver для использования браузера Chrome, мы должны указать путь к chromedriver
driver = webdriver.Chrome ("/ usr / lib / chromium-browser / chromedriver") Чтобы открыть URL-адрес, воспользуйтесь приведенным ниже кодом:
products = [] #List для сохранения названия продукта.
price = [] # Список, чтобы сохранить цену продукта
rating = [] #List для сохранения оценки продукта
driver.get ("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&amp;amp;amp;amp;amp;amp;amp;amp; ; amp; uniq ")
Теперь, когда мы написали код для открытия URL-адреса, пора извлечь данные с веб-сайта.Как упоминалось ранее, данные, которые мы хотим извлечь, вложены в теги
content = driver.page_source
soup = BeautifulSoup (контент)
для a в soup.findAll ('a', href = True, attrs = {'class': '_ 31qSD5'}):
name = a.find ('div', attrs = {'class': '_ 3wU53n'})
price = a.find ('div', attrs = {'class': '_ 1vC4OE _2rQ-NK'})
рейтинг = a.find ('div', attrs = {'class': 'hGSR34 _2beYZw'})
продукты.добавить (имя.текст)
price.append (price.text)
rating.append (рейтинг.текст)
Шаг 5: Запустите код и извлеките данные Чтобы запустить код, используйте следующую команду:
python web-s.pyШаг 6: Сохраните данные в необходимом формате
После извлечения данных вы можете захотеть сохранить их в формате. Этот формат зависит от ваших требований. В этом примере мы будем хранить извлеченные данные в формате CSV (значения, разделенные запятыми).Для этого я добавлю в свой код следующие строки:
df = pd.DataFrame ({'Product Name': продукты, 'Price': цены, 'Rating': рейтинги})
df.to_csv ('products.csv', index = False, encoding = 'utf-8') Теперь я снова запущу весь код.
Создается файл с именем «products.csv», и этот файл содержит извлеченные данные.
Надеюсь, вам понравилась эта статья «Веб-парсинг с помощью Python». Я надеюсь, что этот блог был информативным и повысил ценность ваших знаний.Теперь продолжайте и попробуйте Web Scraping. Поэкспериментируйте с разными модулями и приложениями Python.
Если вы хотите узнать о парсинге веб-страниц с помощью Python на платформе Windows, то видео ниже поможет вам понять, как это сделать.
Веб-парсинг с помощью Python | Учебное пособие по Python | Учебное пособие по парсингу | Edureka
Этот живой сеанс Edureka на тему «Веб-сканирование с использованием Python» поможет вам понять основы очистки вместе с демонстрацией для очистки некоторых деталей с Flipkart.
Есть вопрос о «парсинге веб-страниц с помощью Python»? Можете спросить на едуреке! Форум, и мы свяжемся с вами в ближайшее время, или вы можете присоединиться к нашему обучению Python в Хобарте сегодня.
Чтобы получить глубокие знания о языке программирования Python вместе с его различными приложениями, вы можете зарегистрироваться здесь для онлайн Обучение Python с круглосуточной поддержкой и пожизненным доступом.
Пошаговое руководство по парсингу веб-страниц в Python | Автор: Сара А.Metwalli
Базовый парсинг
Замечательно, теперь, когда мы знаем основы, давайте начнем с малого, а затем наращиваем!
Нашим первым шагом будет установка BeautifulSoup, набрав в командной строке следующее.
pip install bs4
Чтобы познакомиться с основами парсинга, мы рассмотрим пример HTML-кода и узнаем, как использовать BeautifulSoup для его изучения.
BeautifulSoup не извлекает HTML из Интернета, однако он очень хорошо извлекает информацию из строки HTML.
Чтобы использовать указанный выше HTML в Python, мы настроим его как строку, а затем будем использовать другой BeautifulSoup для ее изучения.
Примечание. Если вы используете Jupyter Notebook для чтения этой статьи, вы можете ввести следующую команду для просмотра HTML в Notebook.
из IPython.core.display import display, HTML
display (HTML (some_html_str))
Например, указанный выше HTML будет выглядеть примерно так:
Затем нам нужно передать этот HTML в BeautifulSoup по порядку для создания HTML-дерева.HTML-дерево представляет собой представление различных уровней HTML-кода, оно показывает иерархию кода.
HTML-дерево приведенного выше кода:
Изображение автора (сделано с помощью Canva)Чтобы сгенерировать дерево, мы пишем
some_html_str = "" "
My cool title
Это заголовок
- элемент 1
- элемент 2
< li> item 3
"" "
# Загрузите HTML-код в BeautifulSoup
soup = bs (some_html_str)
Переменная soup теперь имеет информация, извлеченная из строки HTML.Мы можем использовать эту переменную для получения информации из дерева HTML.
BeautifulSoup имеет множество функций, которые можно использовать для извлечения определенных аспектов строки HTML. Однако чаще всего используются две функции: find, и find_all.
Функция find возвращает только первое вхождение поискового запроса, а find_all возвращает список всех совпадений.
Допустим, мы ищем все заголовки
в коде.
Как видите, функция find дала мне тег
. С бирками и всем. Часто нам нужно извлечь только внутренний HTML-текст. Для этого мы используем
.text .Это было просто потому, что у нас только один тег
. Но что, если мы хотим искать элементы списка – в нашем примере у нас есть неупорядоченный список с тремя элементами – мы не можем использовать
find . Если мы это сделаем, мы получим только первый предмет. Чтобы найти все элементы списка, нам нужно использовать find_all .
Хорошо, теперь, когда у нас есть список элементов, давайте ответим на два вопроса:
1- Как получить внутренний HTML-код элементов списка?
Чтобы получить только внутренний текст, мы не можем сразу использовать .text, потому что теперь у нас есть список элементов, а не только один. Следовательно, нам нужно перебрать список и получить внутренний HTML-код каждого элемента списка.